NLP基本概念IV:Transformer及其变种
NLP基本概念系列将以嵌入(Embedding)、注意力(Attention)、生成(Generation)以及Transformer为核心,梳理NLP任务相关的基础概念。在介绍了作为自然语言理解基础的嵌入和注意力以及自然语言生成的相关技术之后,本文将详分析作为NLP领域基础的Transformer模型,并讨论其后的诸多变种。Transformer作为2017年提出,可与CNN、RNN等“上古”模型并列的网络结构,已取代LSTM成为当前NLP领域事实上的标准选择,并有望成为统一图形和语言等众多任务的通用基础。
主要参考:DL for NLP - Mike Lewis、The Transformer Family
Efficient Transformers: A Survey、A Survey of Transformers
The NLP Cookbook: Modern Recipes for Transformer based DL Architectures
各式各样神奇的自注意力机制 - 李毅宏(2022)
2017年,在“Attention is all you need”中Vaswani等人首次提出完全舍弃循环网络,仅由注意力机制实现的Seq2Seq构架,即Transformer。Transformer直译为变压器或变换网络,因其网络结构类似变压器(编/解码模块各自堆叠),但通常不会翻译。狭义上Transformer就是文章所提出的完整Seq2Seq结构,广义上通常指由自注意力、残差连接、层归一化及(逐位)前馈网络所组成的基本模块,与CNN、RNN等网络的结构单元对应。
模型分析
结构分析:有什么
![]()
![]()
![]()
- 注意力:
- QKV:最初阅读Transformer文章时,最困惑的是已经有了QKV,为什么多头注意里还要分别再乘。后来意识到这里QKV只是便于在注意力的计算公式中进行区分,指的其实都是未进行投影的输入。这点其实上图中已明示:自注意力层是不含线性层的,线性层只出现在多头注意力中,对应QKV的投影及最后的合并投影,而QKV本身其实都是输入。
- 多头:多头注意力,相比自注意力不仅是计算多次,而且还进行了额外的投影操作(否则不同头就没区别了)。在原文提出后,这种QKV投影成了注意力机制的标准操作,自注意力通常会理解为包含有投影操作。不过原文中,自注意力是不含投影的,这对理解文中计算复杂度的结果很重要。
- Mask:图中
Mask(opt.)是指可选的掩码操作,在编码器中是不需要该操作的,但在机器翻译的解码器中需逐个生成目标序列,为避免信息泄漏,计算注意力时只能考虑当前单词与之前单词间关联,而不能涉及其后单词,此时就需进行掩码操作。具体的,在得到关联度评分矩阵后,将矩阵对角线之上部分全部设为负无穷,相应的后续softmax操作中注意力权重为0。
- 编码器:多头自注意力 + 残差归一(残差连接+层归一化) + 逐位前馈 + 残差归一
- 多头自注意力:
对输入分别进行QKV投影计算自注意力,并将所有头输出拼接后投影回输入维度(配合残差连接),相当于不同头输出进行加权混合。 - 残差连接与层归一化:
残差连接有助于梯度信息向浅层传递(模型训练),是深度网络的标配,同时还有助于位置信息向深层传递。 - 逐位前馈网络:
注意这里的前馈网络并非全连接,序列输入是逐位(position-wise)变换的,可理解为1×1卷积核的卷积操作(两层),所有输入向量共享网络权重。 - 多层自注意力:同样的结构堆叠六次。
- 随机失活正则:随机失活(dropout)在结构示意图中未展示,用于多头注意力和逐位前馈网络之后(Add&Norm之前)。此外对于输入(嵌入+位置编码)也有随机失活。
- 多头自注意力:
- 解码器:多头自注意力+残差归一 + 多头互注意力+残差归一 + 逐位前馈+残差归一
其中多头自注意模块中为避免自回归生成时信息泄露,当前单词只能考虑与之前单词的关联,即掩码自注意力(Masked Self-attention)。同时多了解码器对编码器输出的注意力(Encoder-Decoder Attention)。 - 位置编码:
由于注意力机制与位置无关,因此需要通过显式编码引入位置信息。位置编码信息可由模型自动学习,缺点是位置编码的长度限制了模型适用范围,当序列长度超过训练所用的编码长度时,模型将无法处理。作者测试发现使用预设的位置编码函数也并不影响最终效果,同时避免了长度限制。
计算分析:复杂度
-
参数量分析
多头自注意力参数主要为多头各自的投影矩阵及合并投影矩阵,取词嵌入维度为,query/key维度为,value维度,head数,则各自投影参数量为,合并投影参数量,合计;逐位前馈网络分共两层(第二层没有非线性激活),取隐层维度为,则其参数量为(忽略偏置项)。文中均取为输入维度除以注意力头数(64=512/8),而前馈网络隐层维度为输入维度的4倍(2048),从而注意力层参数量为、前馈网络层参数量为。虽然注意力层看起来更复杂,但因为前馈网络隐层维度的选取,整体上,模型参数主要集中于前馈网络层,而非注意力层!
此外,如果考虑到嵌入层,Transformer的词表大小为32000/37000,远超词向量维度,参数量自然也远超Transformer模块,相当于5到6层的Transformer模块。从而在网络不深时,整个网络的参数量都集中在输入输出的词嵌入部分,而Transformer中堆叠了6层,参数量刚好与嵌入层相当。
-
计算量分析
先忽略非线性激活及残差归一操作,取词嵌入维度,序列长度,多头注意力QKV投影计算量为O(),QK内积计算量为O(),加权输出计算量为O(),最后合并投影为O(),整体计算量O(),此外,逐位前馈网络(两层)的计算量为O()=O()。对比注意力层与前馈网络计算量,前者超过后者要求,即序列长度超过嵌入维度2倍,在Transformer中嵌入维度为512,GPT取768,BERT取1024,而序列长度通常仅为512。因此虽说自注意力机制复杂度是O(),但模型的计算量同样是集中前馈网络,而非注意力层。这也解释了为什么线性Attention提速只在超长序列(数千)中有效,详细讨论可参考线性Transformer应该不是你要等的那个模型。
与RNN/CNN对比,多头自注意复杂度为O(),相对应的RNN每步操作复杂度为O(),处理整个序列复杂度为O()。CNN处理文本序列时,通常将词嵌入向量逐个按行排布,卷积核整行扫描(横向与词嵌入等长,纵向通常取3或5),即输入输出尺寸为,卷积核尺寸为,从而计算复杂度O()。注意论文中自注意力复杂度O()的结果是不考虑投影操作的。
可以看到自注意力复杂度是要高于RNN/CNN的,其优势在于只需单次的并行操作即可获取距离的关联信息,RNN需要O()次串行操作,CNN需要O()或O()(扩张卷积)层卷积。而自注意力序列长度平方级的复杂度是后续的主要改进方向,但正如前面所分析的,更多时候(序列不是特别长),Transformer计算量主要集中在前馈网络,因此单纯改进注意力提升是有限的。
设计分析:为什么
Transformer结构中有几个不太自然的设计:首先,既然 Attention is all you need,为什么不贯彻到底,前馈网络是必要的吗;其次,为什么只有编码器最后一层与解码器相连,而不是每层都连;最后,为什么位置信息要用奇怪的函数编码。
-
前馈网络的必要性
前面分析可知,前馈网络无论是参数量还是计算量在Transformer中都占据主导,而直接原因在于其隐层维度为词嵌入维度的4倍,这样的超参数选择显然是因为有其必要性,并非简单的“引入非线性”所能解释。Augmenting Self-attention with Persistent Memory中提出前馈网络巨大的参数量可以实现记忆的作用,通过在注意力中引入额外参数作为辅助记忆模块,可移除前馈网络,而不损失性能(这种改进似乎并没有被广泛采纳)。
Are Transformers universal approximators of seq2seq functions?则尝试从理论上论证Transformer的通用近似定理,文中指出虽然自注意力与前馈网络是交叉排布,但由于残差连接的存在,网络可实现自注意层与前馈层的自由组合。其中自注意力层(的堆叠)可实现输入的语境映射(contextual mapping),而逐位前馈网络(的堆叠)则可将语境映射变换为任意预期输出(value mapping),两者配合最终可实现对任意Seq2Seq函数映射的近似。
Attention is Not All You Need又指出单纯自注意力机制倾向于使输出平均化,数学上对应于输出矩阵秩坍缩,秩随深度增加双指数趋向于1。残差连接除了有助于梯度传递和优化,同样对缓解秩坍缩至关重要,而MLP的非线性同样有助于缓解秩探索。
-
编码器解码器连接
在Transformer中解码器只“注意”编码器的输出,即只与最后一层有连接,一个很自然的想法就是为什么不考虑其他编码层,类似的工作有不少,结果有正面有负面。比如Domhan (2018)的结论是没有提升,而He et al. (2018)中将编码器与解码器逐层对齐(Layer Wise Coordination),获得了不错效果。最近的Liu et al. (2020)进一步讨论了编码器与解码器的各种不同连接,结论是通过多种连接组合还是有提升的。
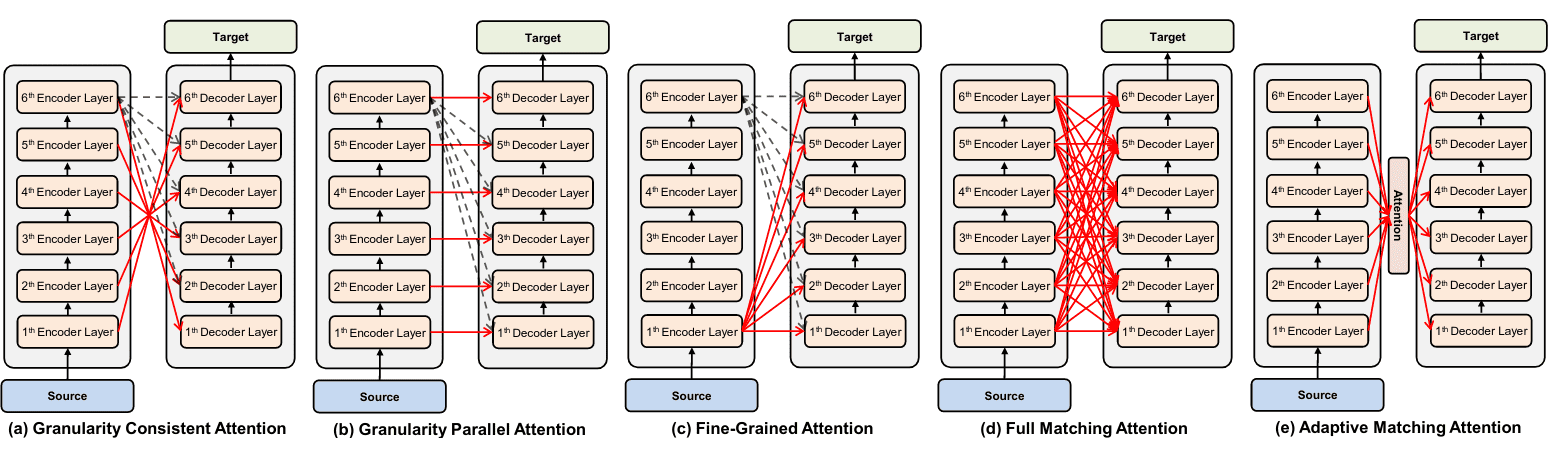 source: Liu et al. 2020
source: Liu et al. 2020 -
位置信息编码选择
虽然文中介绍了引入三角函数位置编码的理由,但之后的模型如GPT, BERT大多还是采用自动学习的位置嵌入。而这些都属于绝对位置编码,Shaw et al. (2018)又提出了相对位置编码,即只考虑Query和Key的相对位置,而非所有输入的绝对位置。这种相对位置编码的思想在之后的Transformer-XL/XLNet, T5, DeBERTa等中得到拓展和应用。不过这些相对位置编码大多依赖于Attention矩阵,无法与线性化的Attention配合,更多介绍可参考苏剑林的这篇博客,其中还提出了“旋转式位置编码”RoPE,某种程度上综合了绝对位置和相对位置编码的优势,可与线性Attention配合,并被最近的PaLM所采用。
Efficient Transformer | Łukasz Kaiser
Transformer 论文解读及源码实现
The Annotated Transformer
技术分析:小细节
-
学习率预热(Warmup)
-
标签平滑(Label Smoothing)
为,软标签,K为类别数,ϵ为小量
→ -
词嵌入缩放:词嵌入乘以
-
层归一化(LayerNorm)
- PreNorm:
Transformer中层归一化与残差连接在一起,位于注意力(及FFN)之后,很快就有研究指出将归一化移至(Chen et al.2018, Baevski & Auli, 2018 etc.)更容易训练,两种做法分别被称为PostNorm和PreNorm。随后的研究发现,PreNorm虽然更容易训练,但其网络深度有水分,下游任务迁移效果往往不如PostNorm,具体可参考为什么Pre Norm的效果不如Post Norm?。
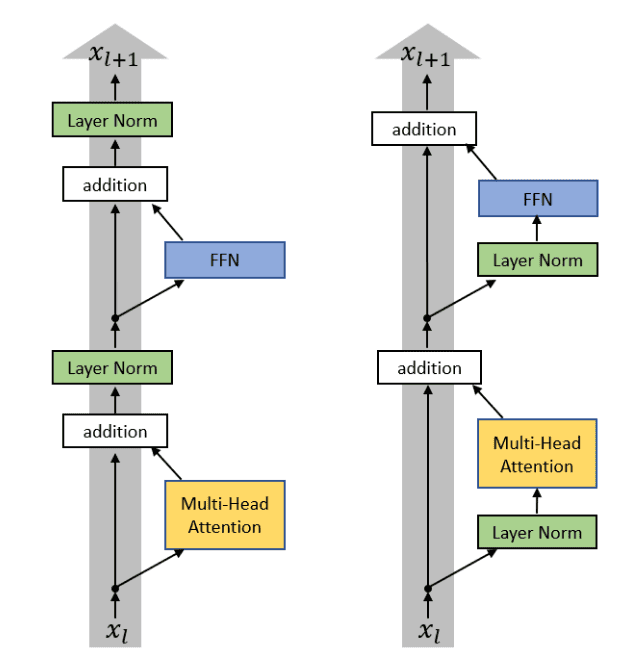
source: Xiong et al. 2020- 其他层归一化的改进还有AdaNorm、PowerNorm等
- PreNorm:
- 论文中注意力层与MLP是依次堆叠的(串行),最近的PaLM中为进一步加快计算,直接将两者并行。此外PaLM还引入了多Query的注意力,即在多头注意力中共享Key和Value,只改变Query。实验发现对模型性能及训练速度都没有明显影响,但会加快模型应用时自回归生成的速度。
-
论文中Query, Key, Value维度取为,以使多头注意力与直接的自注意力计算量相当,同样来自Google的文章就指出增加投影维度可提升模型表示能力。
-
论文中注意力的多个头是在最终拼接投影时进行交流,Talking-Heads Attention则提出在计算注意力权重前就对关联度评分()拼接投影,让各个头在分配权重前就进行交流。
Transformer代码实现过程有有几种mask操作,分别有什么用,在哪一步会调用?
答:对key中padding进行的mask操作,对query中的padding进行的mask操作,Masked Multi-Head中的mask操作。
在训练的时候, 我们是以 batch_size 为单位的, 那么就会有 padding, 一般我们取 pad == 0, 那么就会造成在 Attention 的时候, query 的值为 0, query 的值为 0, 所以我们计算的对应的 scores 的值也是 0, 那么就会导致 softmax 很可能分配给该单词一个相对不是很小的比例, 因此, 我们将 pad 对应的 score 取值为负无穷, 以此来减小 pad 的影响。在 decoder, 未预测的单词也是用 padding 的方式加入到 batch 的, 所以使用的mask 机制与 padding 时mask 的机制是相同的, 本质上都是query 的值为0, 只是 mask 矩阵不同。
mask 机制的原理是, 在 decoder 端, 预测的信息是基于encoder 与以及预测出的单词, 而在 encoder 阶段的, Self_Attention 却没有这个机制, mask 本质是对于 Attention 来说的。
模型变种
A Survey of Transformers- oldsummer
Long-range Transformers
Reformer - Pushing the limits of LM
Transformer模型综述 - 机器之心
Transformer最新综述 - PaperWeekly
Transformer变体最新综述 - 极市平台
扩展输入长度:
Transformer-XL Segment-Level Recurrence
减少总运算量:正比于长度平方
Reformer、Longformer
GBT&BERT
ViT

图片被拆分为16x16的小块(An Image is Worth 16x16 Words),并展开为一维向量(含通道维度)作为“词向量”(之后会进行投影,即“词嵌入”),将整个图片所有子块依次排布,作为“语句序列”。每个图片块内维度对应位置,但图片块间依然缺乏相对位置信息,因此类似语言模型ViT使用位置编码/嵌入引入额外次序。作者尝试了不同位置嵌入方式,发现影响不大,或许是因为分块后,相对位置更容易确定(类比像素级和块级的拼图游戏)。
此外注意力机制的无序本质(重排不变)会打破图片像素间的关联性。
Training the transformers from scratch requires a lot much data than CNN.??? 局部平移不变性
ViT将图片拆分为子块,将整个子块作为“词向量”应用注意力机制
Perceiver (IO)
BERT self-attention 实现
更容易重视全局而非细节,“分辨率”不够??
- Unet的再实现:TransUnet/SwinUNet/nnUNet/nnFormer
Fine tune BERT in 12 lines of code
1 | # Load dataset, tokenizer, model from pretrained model/vocabulary |
框架实现
TensorFlow(tf.keras.layers)中提供有Attention, AdditiveAttention, MultiHeadAttention,分别对应注意力的内积(Luong style)、加法(Bahdanau style)算法以及多头注意力,没有Transformer相关函数。
源码:https://github.com/keras-team/keras/blob/master/keras/layers/attention/
此外TensorFlow Addons(tfa.seq2seq)中同样提供了BahdanauAttention, LuongAttention, MultiHeadAttention等相关对象。区别???
Pytorch(torch.nn)中涉及 Attention 的只有MultiheadAttention。
涉及 Transformer 的有Transformer, TransformerEncoder, TransformerEncoderLayer(self-attn and feedforward network), TransformerDecoder, TransformerDecoderLayer(self-attn, multi-head-attn and feedforward network)。
注意力机制模型:Huggingface Transformers
CV领域自注意力:self-attention-cv ViT,
The Annotated Transformer
Transformer model for language understanding
NLP From Scratch: Translation with a Seq2Seq Network and Attention
扩展阅读
Transformer: A Novel Neural Network Architecture for Language Understanding
Understanding searches better than ever before
Transformers for Image Recognition at Scale
How NLP has transformed vision, biology and beyond
Deep Learning: No, LSTMs Are Not Dead!