NLP基本概念III:Generation | 自然语言生成技术
NLP基本概念系列将以嵌入(Embedding)、注意力(Attention)、生成(Generation)以及Transformer为核心,梳理NLP任务相关的基础概念。I和II中对于嵌入及注意力的介绍涉及的更多是自然语言的“理解”(NLU),而为完成NLP任务,通常还需要另一块拼图——自然语言的“生成”(Natural Language Generation, NLG)。本文将讨论NLG的常见技术,具体将涉及以下概念:Autoregressive、Beam Search、Top-k/p Sampling、Teacher-forcing、Exposure Bias、Scheduled Sampling;Non-autoregressive Generation、Multi-modality problem;BLEU;Out-of-Vocabulary(OOV) Word、Sub-word technique、Byte Pair Encoding(BPE)、WordPiece/SentencePiece。
主要参考:NLG -CS224n (2021)、NAR Generation - 台大(2020)、、Subword Models - CS224n (2019)
自回归生成AR
对于机器翻译任务以及更广泛的(条件)语言模型,其最终目标通常是输出概率最大化的文本序列,即自然语言生成(NLG)任务。但基于神经网络的语言模型每次只能由序列上文获得当前单词概率,具体可参考NLP基本概念I中对语言模型的介绍。为了得到完整的文本序列,通常做法是得到输出单词后,将其追加到输入中,用于生成后续单词:具体的,在获得后,可将其作为输入计算,进而得到,迭代延伸,直至输出终止符<EOS>。这在循环网络中很容易实现,因为全部上文信息都被在压缩在隐状态中,因此只需基于当前时刻隐状态及输出,计算新的隐状态及对应输出,依次循环即可。
这种基于之前输出依次产生后续输出的方式被称为自回归(Autoregressive)生成,最早源于统计中的时间序列问题。基于语言模型的序列生成是典型的自回归,且契合RNN顺序执行的特点,因此自回归生成是NLG任务的默认选择。而除了RNN,自回归生成也可用于CNN,如基于因果卷积的PixelCNN(图片生成),以及基于扩张(因果)卷积的WaveNet(语音生成)等。
序列解码
有了序列生成的整体框架,如何由语言模型输出的单词概率从词表中选择出具体的单词依然是一个开放性问题。最简单的做法是每次只保留概率最大的单词,但这并不能保证输出序列的整体概率最大。尤其是可以想象如果其中某步选择出错,此后建立在其之上的输出也大概率不是好的选择,即便模型本身没有问题,偏差也将不断累积放大。而如果将所有可能性展开,从当前输出开始,下一个单词有很多选择,选择每个单词后,又各自对应很多不同的下下个单词,整体呈现出指数级扩展的树状结构。我们的期望是找到这棵树所有分支中概率最大的那条路径,遍历所有分支显然不现实。而每次选择最大概率单词则相当于直接的贪婪算法,不能保证全局最优,因此又有其他一些改进的近似算法,常见的序列生成方式有:
- 贪婪搜索(Greedy Search):每次只保留当前概率最高的单词,直至概率最高输出为
<EOS>,则终止计算,输出整个序列。 - 集束搜索(Beam Search):保留当前概率最高的 m 条路径,对其中每条路径,预测下一个单词,计算每条路径的整体概率(序列所有单词条件概率的乘积),继续保留其中概率最高的 m 个,如此重复。事实上每条路径只需考虑预测单词中概率最高的前 m 个,最终概率最高路径的必然位于 m2 个序列中。集束搜索虽然不能确保全局最优,但相比贪婪搜索显然是更好的,这其中有一些需要注意的问题:
- 集束搜索对比的是序列整体概率,而不同序列结束位置不定,长短不一。随着序列增长,概率相乘后整体概率是降低的,显然这对长句是不利的。因此实际中会使用句子长度平衡权重:,简单粗暴但有效(归一化T还可加指数)…
- 其次,由于不同序列结束位置不同,意味着需要当前概率最高的 m 条路径全部结束(预测出
<EOS>)模型才能终止。实际中通常会预先设定作为终止条件的序列长度或序列数目,当序列长度或结束的序列数达到预设,就终止计算,并从所有已结束序列中挑选最佳选择。 - 集束搜索的结果更接近全局最优,从实现语言模型目标的角度看并没有问题。问题在于,实际的人类语言并非语言模型模型所假设的始终取概率最大,而是存在很大波动性(如下图所示)。因此对于翻译或者文本总结等内容相对可预期的任务,集束搜索获取或许是不错的选择,但对于开放生成任务则不太合适。最明显的后果是,使用集束搜索时,模型易出现相同语句片段的机械重复。
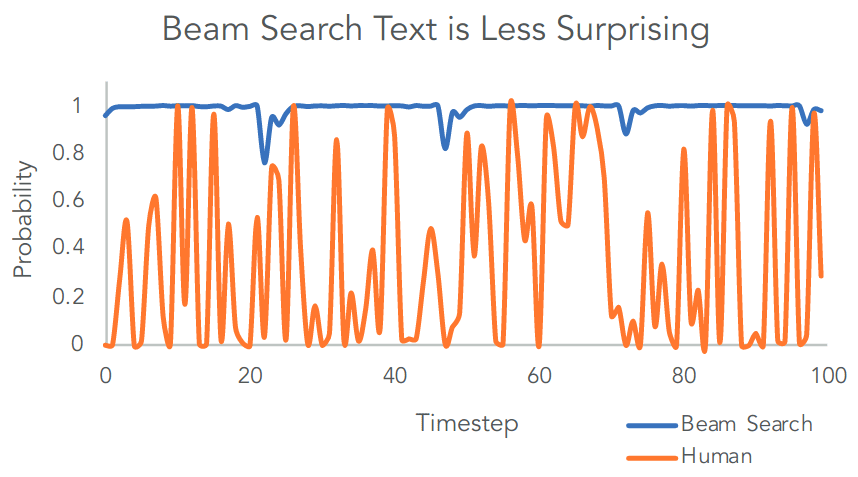 Beam Search v.s. Human(source: Holtzman et al. 2019)
Beam Search v.s. Human(source: Holtzman et al. 2019)
- 随机采样(Sampling):为应对集束搜索刻板重复的缺点,人们引入了随机采样,每次依照词语的概率从中随机选择一个单词。看起来是比贪婪搜索更差的选择,但目标已经不是最大化输出序列的概率,而是输出文本有相对较大的概率同时保持多样性。
随机采样的缺陷在于依然有概率选择到不合适的低概率词汇,从而对模型输出产生破坏性效果,具体表现为生成的文本语无伦次、胡言乱语。最直接的解决办法是在计算softmax时引入温度参数,提升大概率词汇权重 。温度参数在0到1之间取值,而随着其趋近0,将增大,做为的指数函数,取值较大者最终权重将被放大,增强区分度。不过随着区分度增加,采样的多样性下降,同样会出现机械重复的问题。 - 限制性采样(Top-k/p Sampling):随着语言模型增大、数据量增加,在温度参数之外人们又提出了更为直接的筛选策略:Top-k(Fan et al. 2018) 和 Top-p(Holtzman et al. 2019)。前者是保留概率由高到低的前k个选项(Top-k),概率归一化后从中采样;后者则是保留概率由高到低总和为p(包括刚超过p)的所有选项(Top-p),概率归一化后从中采样,也被称为核采样(Nucleus Sampling)。后者相比前者的优点在于可根据概率分布进行一定程度的自适应调整:当概率集中在少数几个单词上时,只会保留这几个单词;而当概率分布相对均匀时,则会自动扩展至更多单词,如下图所示。
 Top-p Sampling(source: CS224n)
Top-p Sampling(source: CS224n)
Top-k、Top-p可联合使用,限制单词数上限,同时保持灵活性。Top-k/p采样还可与集束搜索结合:同时保留m条路径,对每条路径,选择预测单词的Top-k/p部分,然后计算全部路径的整体概率,并依概率从中采样m条路径(e.g. Holtzman et al. 2018)。最后,也有研究指出只需要调整损失函数,集束采样也可避免重复问题(Welleck et al. 2019),此外在Top-k/p采样中始终包含<EOS>或在集束搜索时基于一定策略自动终止生成,有助于生成序列的连贯性(Welleck et al. 2020)。
暴露偏置
理论上,上述自回归生成在模型训练及测试阶段均可应用,但自回归生成的问题在于后续输出依赖之前输出,这其中存在很大的不确定性,中间任何一环出错,整体偏差就会不断放大。因此实际中为加快模型收敛速度,在训练阶段通常并不会采用自回归生成。即不会将模型当前输出作为输入生成后续输出,而是将真实的当前词语作为输入生成后续输出。这被称为教师引导(Teacher-forcing)策略:始终使用真实的上文信息预测后续输出,并与预期结果对比计算损失,使模型的偏差始终受到控制,而不至于循环放大,增加学习的稳定性。尤其值得注意的是,在训练阶段并不是输出<EOS>就停止后续输出,将整个序列与预期输出对比。而是会以预期输出为准,直至预期输出全部用作输入,引导预测后续输出后,才将对应的全部输出用于计算损失,而不管其中有没有或有多少<EOS>。

另一方面,在测试或应用阶段并没有可作为输入的预期输出,只能采用自回归生成。这意味训练和测试的外部条件(数据分布)不一致,而在“温室”里长大的模型会更脆弱,也就是存在所谓的暴露偏置/曝光偏差(Exposure Bias)。目前主要解决办法为计划采样(Scheduled Sampling):每次以一定概率选择使用预期输出作为当前时刻输入,未选中时则以前一刻输出作为输入,而这个概率会随着模型训练有计划的逐步降低。即最开始模型一无所知时,会更多的由老师指导,随着模型学习的深入,表现变稳定的同时逐渐减少指导,从最初的教师引导逐渐变为自主学习(自回归)。这种由易到难的渐进训练方法属于课程学习(Curriculum Learning)策略的一种。在课程学习中,参照人类教学时的课程设计,训练数据会根据处理难度由易到难地提供给模型学习,增加训练稳定性,加快收敛,同时也有助于提升模型鲁棒性和泛化能力。
计划采样的问题是,输入的选择要用到前一刻模型预测输出,这就意味着无法并行。这在RNN中并没有问题,但对于Transformer其底层是可以并行的,因此人们又发展了适合并行的计划采样策略:先通过教师引导的方式由解码器(并行)生成一组输出;之后再参照计划采样重新(并行)解码,随机选择真实输出或之前预测输出作为输入,并随着训练进行逐步降低真实输出的比重。其中预测输出作为输入时,作者尝试了多种选择:最简单的是选择概率最大的单词(的嵌入向量),其次是将Top-k(k=5)的词向量概率加权平均,或将所有词向量概率加权平均(softmax会引入温度参数,增加大概率词语权重),以及概率采样等等。
最后,除了计划采样,人们也提出了其他一些缓解暴露偏置的训练策略。Lamb等人提出的 Professor Forcing 中引入生成对抗,使教师引导和自回归学习的隐状态分布尽量一致。又或者直接基于GAN实现文本生成,如SeqGAN。
非自回归生成NAR
自回归生成的问题在于需要逐元素的顺序生成,无法并行加速。之前受限于RNN自身顺序执行的特性,这一问题并不重要。而在Transformer提出后,解码器已不存在顺序执行的限制,在训练时基于Teacher-forcing可实现并行输出,但在测试时自回归生成却只能顺序执行,如何更快的并行输出就成为一个改进的重点。基于隐变量的自编码器AE及生成对抗GAN作为主要的非自回归生成模型,在语言序列生成上效果不理想,因此很多针对语言生成(以及图像生成)的非自回归生成方式被提出。这部分主要参考李宏毅机器学习课程中Non-autoregressive Sequence Generation(选修)一节内容。
非自回归生成的两个首要问题是:序列长度的确定以及解码器输入的选择。在自回归生成中序列长度由<EOS>标识自动确定,模型预测出<EOS>便终止生成,放弃自回归则意味着需要在输出前就确定序列长度;其次,无论是RNN还是Transformer,解码器都需要有输入用于产生输出,自回归可以使用之前时刻输出,非自回归需要使用其他输入信息。最简单的做法,是长度由编码器预测,而解码器输入取为位置编码/编号。
一切看似完美解决,但非自回归生成真正的问题在于语言的多样性(multi-modality):同一个意思可以有多种不同的表达。尤其是在翻译中,同一句英文可以翻译成多种中文表述。在自回归生成中,由于后续输出依赖之前输出,可以保证最终输出是其中某一种自洽的表达;但在非自回归生成中,每个单词输出相互独立,且没有统一的隐变量指示输出表述的取舍,最终结果大概率是多种表述的混合平均,变得不伦不类。基于编码器得到的序列长度在一定程度扮演隐变量的角色,可对输出表达做出一定取舍,但这种限制还是太弱。
以Happy为例,翻译为“高兴的”或“快乐的”都可以,两者基本等价。而由于每个字都是独立生成,“高乐的”或“快兴的”也将是可能的输出组合,显得莫名其妙。GAN虽然也是非自回归生成,但其判别器保证了生成结果的整体自洽性,且其随机噪声输入事实上预先决定了模型输出的取舍方向,最终生成结果会对应某个自洽的结果,而非众多结果的混合。
Gu et al, 2017最先提出了非自回归生成,指出了语言的多样性(multi-modality)问题,并提供了三种缓解策略:
- 辅助隐变量(Fertility predictor):编码器在正常编码外,每个输入会额外对应预测一个数字,指示该输入对应的输出字符数(输出长度);之后,编码器的输入按相应数字重复0至多次作为解码器输出(解码输入)。通过指定每个输入对应的输出字符数,对输出做出了更严格的限制,但其实还无法应对上面的例子(而且似乎也无法很好应对多个输入对应一个输出情况)。
- 知识蒸馏(Knowledge distillation):将已使用训练好的自回归语言模型(Teacher)的贪婪搜索输出作为非自回归模型(Student)训练目标。由于是贪婪搜索输出,因此结果相对稳定,没有那么复杂的多样性,从而限制了非自回归模型学习到的输出。(感觉这并不是好选择,因此直接从源头扼杀了模型的多样性。)
- 噪声解码(Noisy parallel decoding):编码器预测数字时给出的是softmax概率,因此可采取采样的方式,得到不同的预测数字,进而产生不同的输出序列,之后可以对输出序列整体打分(用训练好的自回归模型),以减少不自洽的输出序列。
在此后,众多非自回归生成策略被提出:
- 迭代修正(Iterative Refinement):迭代过程中句子长度不变
- Lee et al. 2018:在Gu et al, 2017基础之上,将解码器输出文本再重新作为解码器输入,迭代修正。实现上会用单独解码器用于迭代,优化目标除了逼近实际输出(Latent variable model),还引入去噪声过程(Denoising Autoencoder)。
- Ghazvininejad et al. 2019(Mask-Predict):训练时解码器会类似BERT,随机MASK一部分Teacher-forcing的输入;测试时编码器会预测输出序列长度,解码器输入则全部取MASK(总数对应编码器预测长度)。在得到输出后,将其中概率值相对较低的单词替换为MASK,重新输入解码器,迭代优化。每次MASK的词数则会根据迭代次数线性衰减。
- 迭代插入(Insertion-based):迭代过程中句子长度可变
- Insertion Transformer:每次在之前序列基础上决定是否插入以及插入哪个词:最初为空序列,可理解为在
<BOS>和<EOS>之间插入字符,之后在中间词左右两侧可选择插入新词,依次迭代。训练时,可从预期输出序列随机选择一些词作为初始输入,之后迭代预测插入词(不插入则输出指定标记)。对于连续多个空位情况,计算损失时需同时考虑所有词;而通过对窗口加权,可引导模型优先预测位于窗口中心的词。测试时则从空序列开始依次插入预测词,原本O(n)次迭代的自回归变为O(log2n)次迭代。
迭代插入并不能一次性获得输入,算是半自回归,但从线性到对数级的提升依然很出色的,最终迭代次数并不一定比迭代修正多(10次迭代序列长度就可达1000量级),且其预测表现更好。 - KERMIT:去掉了Insertion Transformer中的编码器部分,直接将输入与目标输出拼接作为解码器输入。训练时,目标输出部分参照前者,随机取部分词作初始输入,预测插入词;测试时则从零开始预测输出。与BERT的不同在于,BERT指定了掩码位置(MASK标记),插入预测则不提供掩码信息,由模型决定是否插入新词。而且KERMIT中,输入与输出真正实现了对称:根据输入及掩码选择,模型可单独学习输入P(x)或输出P(y),也可由输入预测输入P(y|x)或由输出预测输入P(x|y),又或者同时学习输入输出P(x,y)。因此不同于BERT,KERMIT是可用于生成任务的。
文章中在英文与德文间分别进行了单向、双向和联合预测训练,结果是联合预测的翻译表现,略差于双向预测,后者又略差于单向训练。但如果在联合预测训练后叠加单语言预测训练及针对单向翻译的微调,模型最终表现明显提升。
- Insertion Transformer:每次在之前序列基础上决定是否插入以及插入哪个词:最初为空序列,可理解为在
- 插入删除(Insert + Delete):插入新词同时删除旧词
- Levenshtein Transformer:测试时,解码器会对输入依次三个操作:对每个单词判断是否删除;对删除单词后的序列,预测单词间插入多少个新词;一次性预测所有插入词(以
[PLH]placeholder做为输入),之后迭代优化。训练时则使用强化学习,具体的是模仿学习(Imitation Learning)策略,进行训练。具体的会人为制造一些需要插入或删除的句子,模型会基于字符串编辑距离(Levenshtein distance)算法的指导学习插入或删除操作。
- Levenshtein Transformer:测试时,解码器会对输入依次三个操作:对每个单词判断是否删除;对删除单词后的序列,预测单词间插入多少个新词;一次性预测所有插入词(以
- 时序分类(CTC-based):Connectionist Temporal Classification
- CTC主要用于语音识别,基本思路是每个语言片段对应一个输出,输出可以为空,也可相同;将相邻的相同输出合并,并删除空输出即得到最终输出。
- CTC可一次性产生输出,也意味无法修正潜在错误输出,因此Chan et al. 2020中提出可迭代修正的Imputer模型,操作上有点类似BERT和KERMIT,将语音信息与MASK的文本输出相加后输入模型,迭代更新输出文本,测试时从全MSAK的文本序列开始迭代即可(通过一些策略可限制迭代次数)。
- 将CTC/Imputer用于文本任务时,可对输入序列进行上采样,之后按前者操作预测输出。具体可参考Libovický & Helcl 2018 / Saharia et al. 2020
评价指标Metrics
语言生成任务因语言本身的特性,并有固定的标准答案,而人力检查不仅且费时费力、成本高,且主观性很强,难以保证标准一致。BLEU(Bilingual Evaluation Understudy)是目前机器翻译及更广泛的文本生成任务中常见的评价标准。
BLEU中每个测试输入会提供一组人工参考输出文本,评价时,针对模型输出中的各单词,逐个查看其是否出现在任一参考文本中,计算生成序列全部单词的命中率作为评分(0~1)。注意,对比采用的是词袋模式,即不考虑词语出现的位置次序。除了单个词语(uni-gram),这种检查还会扩展至任意连续的多个单词(n-gram),用于检查生成文本的连贯性,通常会取到4-gram。不过这其中存在一些需要注意的问题:
- 重复:将出现在参考文本中的单词或短句不断重复大概率不是期望的输出文本,但命中率却是1。解决办法是以单词在参考文本句子中出现的最多次数作为该单词命中次数的上限;
- 短句:计算命中率时会除以序列长度,因此长句自带惩罚,但短句却并没有。截取参考文本的一部分,虽然句子不完整,命中率却将是1。解决办法是对短句施加额外惩罚,假设最短的参考文本长度为,预测输出长度为,取简短惩罚(brevity penalty) 。
最终n-gram评分,总分,其中为对于不同长度连续词语的权重,如可取,而N一般取为4。最终的BLEU评分乘以100,范围从0-1变为0-100。
注意,(条件)语言模型在训练时损失通常是交叉熵,要求预测输出与目标输出精确匹配。但如前面所说机器翻译及其他常见文本生成任务都并有固定的标准答案,考虑到语言的多样性,BLEU显然是相对更合理的评价指标。交叉熵损失其实过分强调了参考答案的正确性,扼杀了输出文本的多样性,与实际目标并不匹配(Loss-Evaluation Mismatch)。实际表现上,测试时模型容易出现相同词语或短句的机械重复,尤其是用贪婪或聚束搜索时。而BLEU的问题在于其不可微分,难以直接用于模型训练,有一些工作(如Ranzato et al. 2015)尝试通过强化学习实现以BLEU为目标的模型优化。
最后,显然BLEU也并非完美标准:一方面任何n-gram未匹配评分都将直接降为0,随着n的增加这一要求也愈加苛刻,因此n不能太大;另一方面n-gram都匹配也并不能确保文本的流畅正确、逻辑通顺这些重要但难以量化的要求。因此人们又发展了很多其他评价指标以及针对专项任务的指标,各有侧优劣和重点,如基于召回率的ROUGE,同时考虑准确率和召回率的METEOR,以及针对图片描述任务的CIDEr、SPICE等等。又或者可借助其他模型进行评价:将语言翻译、图片描述或文本摘要模型的输出,传递给一个依赖相关文本信息,且在正常文本上表现良好的模型,则后者的最终表现可作为前者的评价指标,但此时需要保证作为评价模型的任务能反映真实的评价标准。更多关于文本生成任务的评价方法可参考这篇综述。
海量词汇处理
语言模型预测单词概率时需要对整个词表计算softmax,而随着语言模型涉及的词汇量增加,其计算也愈发成为瓶颈。
- 调整Softmax计算:具体可参考参考NLP基本概念I中Word2Vec部分的介绍
- 层级Softmax(Hierarchical Softmax):将|V|分类问题拆解为O(log2|V|)次的二分类问题
- 负采样(Negative Sampling):在正确候选词外,再随机选取少部分单词作为负例计算Softmax,更为简单高效
- 压缩词表:减少计算的单词数,限制模型输出维度
- 直接移除不常用词汇,只关注核心的常见单词,对不常见词汇输出预设的未知标记
<UNK>(unkown)。这是常用做法,而其问题在于为得到最终输出需额外策略处理未知词汇/表外词汇(Out-of-Vocabulary Word, OOV Word)。 - (Jean et al. 2014) 分批处理训练数据,每批数据对应的输出词汇量限制为|V’|(比总词汇量|V|少一个量级以上),各批次数据共用模型依次训练。其问题在于最终模型输出与词汇间不再是一一对应,测试时将无法知道输出概率对应确切的哪个单词,需要从一堆可能的组合中挑选最终输出序列。
- 直接移除不常用词汇,只关注核心的常见单词,对不常见词汇输出预设的未知标记
- 基于字母/字符(Character)的模型:以字而非词作为序列最小单位(Ling et al. 2015)
- 相比词粒度,字粒度可显著减少词表大小,且有助于应对OOV词。其缺点也很明显:会显著增长序列长度,增加模型处理负担;而且相比有意义的词,直接处理字要求模型有更强的表示能力。作为折中人们发展出了混合模型(词+字)和基于词片段(子词)的模型。
- 混合模型:结合词与字模型的优点 (Luong et al. 2016)
- 普通词粒度模型上叠加字粒度模型,专用于处理未知字符
<UNK>的输出。
- 普通词粒度模型上叠加字粒度模型,专用于处理未知字符
- Sub-word技术:将词拆解为字符以及n-gram字符片段
- 直观理解就是参照构词法,将单词拆解为词根、词缀等,以压缩词表数量。不过实际中并不会考虑构词法,而是直接基于统计分析或者语言模型进行片段划分,主要的算法有BPE、WordPiece、ULM、SentencePiece等。
- (Sennrich et al. 2015) 字节对编码(Byte Pair Encoding, BPE),从字母(uni-gram)开始,将语料中出现频率最高的字母对(bi-gram)加入词典,之后将语料中出现频率最高的字典元素对(字母及之前加入的n-gram)加入字典,如此循环直至语料中不再有未录入字典的元素对或者字典元素达到预设数量|V|。整个过程先要对语料进行词语级分词,之后基于BPE建立字典,最后基于字典将语料进一步分解为词片段token序列。
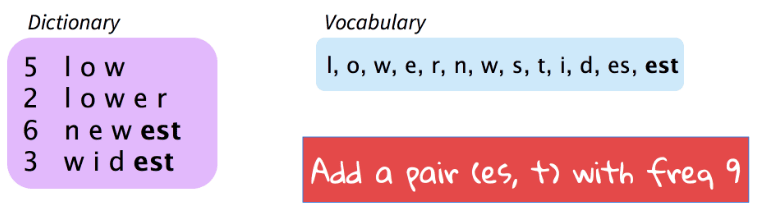 BPE(Source: CS224n)上图所示,语料库中包含5个low、2个lower、6个newest、3个widest。字典中首先包含所有字母(uni-gram),
BPE(Source: CS224n)上图所示,语料库中包含5个low、2个lower、6个newest、3个widest。字典中首先包含所有字母(uni-gram),l, o, w, e, r, n, w, s, t, i, d,语料库中频率最高的字典元素对为es(和st),共出现9次,取es加入字典。字典变为l, o, w, e, r, n, w, s, t, i, d, es,此后语料中的es对将被视为整体(单个字典元素),而不再是单独e和s。当前未录入字典的频率最高元素对为est,共出现9次,取est加入字典,如此循环扩展,每次追加一个频率最高的元素对。 - 除了基于元素对频率确定分词的BPE,人们还提出了基于语言模型划分子词的方法,如 WordPiece(Schuster et al., 2012)、Unigram Language Model(Kudo 2018) 和 SentencePiece(Kudo & Richardson 2018)。BPE和WordPiece的频率统计都是基于词的,需要预先进行分词处理,拉丁语通常是以空格为分解,但以CJK为代表的亚洲文字却并非如此。相对的,SentencePiece无需预先分词,可直接处理段落文本,将输入序列视作统一编码(Unicode)字符串(包括空格),从而实现所有语言序列的可逆处理。
- 这些不同子词拆分算法在最近的NLP模型中得到广泛应用,Transfomer, GPT, XLM中使用了BPE算法,BERT, DistilBERT, Electra中使用了WordPiece,而ALBERT, XLNet, T5中则使用了SentencePiece。
- 注意:由于BPE和WordPiece子词划分基于词的,因此需要在单词的边界(或内部)插入额外的符号,以便于确定在那些位置插空格,从而可由子词组合回完整单词,比如BPE中通常在单词结尾加
</w>,BERT中则选择在单词内插入##。
- 表外词处理:Out-of-Vocabulary Word, OOV Word
- 表外词汇是始终伴随语言模型的一个问题,尤其是在词库大小有限的情况下。基于字符或Subword技术实现的开放词库有助于缓解该问题,但还会存在少见的外来词汇/名字,数字或特殊符号等等情况。
- 复制输入:基于语言模型实现输出和输入的对齐(Luong et al. 2014),或者基于注意力机制(指针网络)确定表外词汇所对应的输入文本(Gulcehre et al. 2016),之后根据词汇对应表确定翻译,或是直接使用输入文本本身/音译。不过这种对齐也并不是很不可靠。
- 随着大规模预训练模型的出现,一个模型处理所有语言任务逐渐成为现实,而为了应对丰富多样的各种语言,即便是字符级词表也显得过于庞大,Unicode本身包含的字符就有十多万,如果再考虑Subword组合,词表还要进一步扩张。于是人们也开始考虑直接处理二进制字节的方案,以实现真正语言无关的统一模型,比如GPT-2中就使用了字节级别的BPE算法用于输入切分,而ByT5更是选择直接处理原始字节(token-free)。
更多实践技术
多语言互译
2016年Google的团队基于其NTM系统(GNTM)实现了用单一系统进行多语言互译,只需要在输入文本时增加一个指示目标语言的标记(token),即可实现自动翻译。整个模型在所有翻译语言间共享参数,不仅提升了翻译性能,而且可以实现零学习(zero-shot)的翻译,即在没有直接学习的两种语言间实现翻译。只需要借助中间语言,如模型在只学习了英语与俄语及乌克兰间翻译后,便可自动实现不错的俄语与乌克兰间的翻译。这说明模型学习到了独立于语言的内部表示,人类离巴别塔更近一步。而在以BERT为代表的大规模预训练出现后,这种多语言模型更是变得很常见,如mBERT、XLM-R、mT5等。
反向输入
文本序列生成任务中,最初的词语通常不确定性会很高,而随着序列增长,后续文本由于受到前面的限制会相对稳定,因此好的开始非常重要。尤其是对于机器翻译任务,目标序列文本初始部分通常对应输入文本初始部分,而RNN对于初始部分记忆会随着序列增长而下降。因此早期基于单向RNN的Seq2Seq模型中,编码器通常会反向处理输入文本,从而保留尽量多输入文本起始部分的信息。而有了注意力机制之后这一切都不再重要,输出会自动聚焦所对应的输入。
扩展阅读:
NLP中不同评价指标的逻辑意义?
NLP中的Tokenization方法总结
Language Modeling - NLP Course | For You
How to generate text - Huggingface