NLP基本概念I:Embedding | 语言模型与词嵌入
NLP基本概念系列将以嵌入(Embedding)、注意力(Attention)、生成(Generation)以及Transformer为核心,梳理NLP任务相关的基础概念。作为开篇,本文将以Embedding概念为中心,梳理NLP领域从词嵌入到大规模预训练模型的发展历史,其中涉及了语言模型LM、统计语言模型SLM、神经语言模型NNLM、分布式表示、词嵌入Word2Vec / GloVe / fastText、语句嵌入Skip-thoughts / Quick-thoughts、动态嵌入CoVe / ELMo / GPT / BERT,以及BERT之后预训练语言模型PLM的诸多变种和微调(Fine-turning)、提示(Prompting)等模型调整技术。
主要参考为相关论文(见文内链接),其他参考:
From static to dynamic word representations: a survey
A Survey on Contextual Embeddings
在最近的以2012年AlexNet为起点的深度学习浪潮中,在ImageNet等大规模数据集的加持下,机器视觉领域一马当先,发展出了利用大规模数据集预训练模型,再结合迁移学习针对具体任务微调(fine-tuning)的通用做法。如何在NLP领域实现类似的通用预训练模型自然成为人们的追求方向,并最终迎来了代表性的GPT和BERT以及随后的超大模型军备竞赛,本文回顾了实现这一目标的探索历史。
基础概念
NLP领域相对通用的编码概念始于词嵌入,并以Word2vec为代表。在此之前NLP中并没有统一的文本表示方法,作为开拓者的前人提出了很多策略:从One-hot编码单词,到Bag-of-words表示文本;从K-shingles的文本切分,到基于序列标注的语义分割;从tf-idf基于词频的权重计算,到text-rank借鉴page-rank的权重计算;从基于SVD纯数学分解词文档矩阵的LSA,到pLSA中用概率手段来表征文档形成过程并将词文档矩阵的求解结果赋予概率含义,再到LDA中引入两个共轭分布从而完美引入先验…而这其中又有两个模型最值得关注,其中一个是作为一切起点和基础的统计语言模型,另一个则是首个基于神经网路实现词嵌入的NNLM。
SLM(1970s)
介绍基于神经网络(NN)的语言模型之前,先看下作为基础的统计语言模型(SLM)。统计语言模型的出发点很简单:一段文本的合理性可根据其出现的可能性加以判断。最简单粗暴的解法是,将语句视为整体,对相关语言的历史语料做统计,计算当前语句的概率,但这显然不现实。另一种思路则是将语句视为单词序列,由概率乘法:
语句的概率被转化为单词的概率,看起来简化不少,其中就是在语料中的概率,并不难统计,也不难计算,但随着条件概率中作为条件的单词增多,概率的估算也愈加困难。
于是人们又引入了马尔科夫假设:任意单词只与其前面的单词相关。从而:
这就是统计语言模型中的二元模型(bi-gram Model)。显然上述假设过度简化了,一般的可假设任意单词只和其前面n-1个单词相关,相应的模型被称为n元模型(n-gram Model)。统计语言模型实现了语言统计分析的突破,但其本身依然有很多问题:
- 为在语料中的共现次数,计算虽不复杂,但一切有效的前提是大数定律。而实践中低频词汇的小概率事件并不少见,如共现次数为0并不能断定 ,又如和都为1也不意味,这其中需要很多技巧对概率进行调整和平滑处理。当考虑3元模型时,,如果为0,将无法计算概率,还需要避退(backoff)处理。随着的增加上述问题也将愈发突出。
- 虽然有一般的n元模型,但现实中n取值仍然很小,最常见的是三元模型(tri-gram)。原因在于n元模型的空间复杂度(存储)为,时间复杂度为,其中|V|为语言的词汇量,通常在十万、百万量级,随着n的增加资源消耗指数级增加,效果提升却越来越小,因此捕捉语言中更长程的上下文依赖仍然需要新的模型。
- 统计语言模型无法表征词语间语义上固有的相似性(近义词),而人们很早就意识到这种相似性的重要性,并尝试提取这种相似性(如WordNet数据库)。
NNLM(2001)
Bengio在2001年提出了基于NN的语言模型NNLM。对于一般的n-gram语言模型,难点在于的计算,对应于基于序列中若干连续单词预测后续单词(概率),在基于NN的实现上可视为多分类问题,使用softmax函数计算不同单词(语料库中所有单词)作为的概率,并以交叉熵作为损失。
根据历史惯例,NLP领域更常用的是名为困惑度(Perplexity)的量作为网络目标函数:取值为整句概率的倒数开N次根(N为句子长度),或者说是句子中所有单词n-gram概率导数的几何平均
上述公式不太直观,又是导数又是开根号,很奇怪。但考虑最佳情况,模型预测与目标完全一致,,则此时模型困惑度为1;而最差情况,模型预测完全随机,,则此时模型困惑度为|V|。因此困惑度取值介于1到|V|,代表了模型对于输入语句的困惑程度:如果输入完全符合模型预期则困惑度最低,而如果模型完全不“理解”输入,无法做出合理预测则困惑度将变高。而如果对困惑度取对数,正是分类问题中常见的交叉熵损失,两者殊途同归,在数学上完全等价。
此外,需要强调的是“语言模型”(Language Model, LM)是专有名字,专指预测语言序列/计算语言序列概率的任务,而非任意的自然语言相关的模型。对于基于NN的语言模型而言,对应的损失函数就是常见的交叉损失,神经网络需要根据输入对每个单词依次计算,并对序列中所有词汇计算整体损失。由于预测目标直接来自训练语料,无需人工标签,因此“语言模型”属于无监督(自监督)学习任务。而由逐个预测单词变到预测整个输出序列,涉及自然语言的生成技术,具体可参考NLP基本概念III:Generation | 自然语言生成技术。
具体的,NNLM是一个三层神经网络,如下图所示:输入时通过查表(table lookup)/将One-hot编码与编码矩阵相乘得到分布式表示向量,并拼接在一起(没有激活),经后续隐藏层后最终由输出层计算softmax概率(维度为词库大小),如下图所示。训练的目标是最大化取正确单词的概率(对应于交叉熵损失)。注:图中绿色虚线有点类似ResNet的捷径。
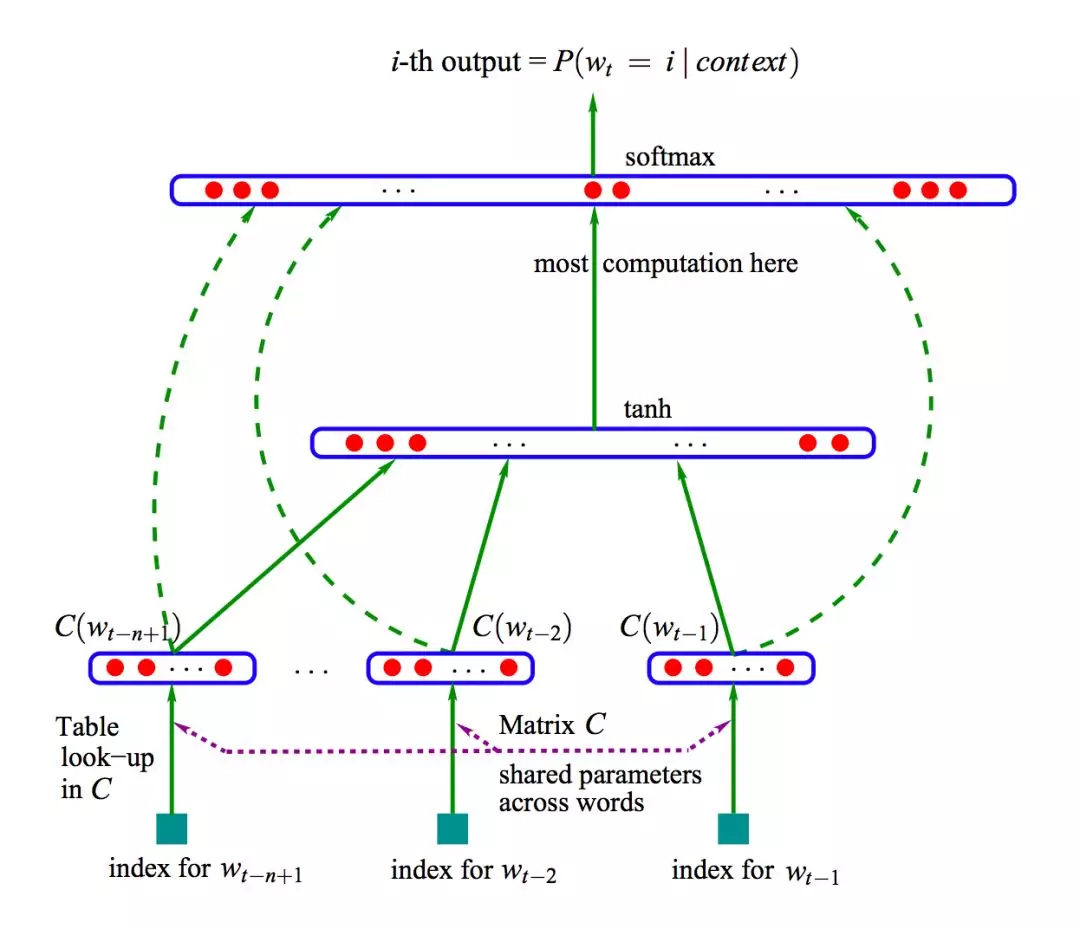
It is a successful large-scale application of the same idea that was advocated in the early days of connectionism (Hinton 1986; Elman 1990). … The idea of using neural networks for language modeling is not new either. In contrast, here we push this idea to a large scale, and concentrate on learning a statistical model of the distribution of word sequences, rather than learning the role of words in a sentence.
The idea of discovering some similarities between words to obtain generalization from training sequences to new sequences is not new. In the model proposed here, instead of characterizing the similarity with a discrete random or deterministic variable(clustering), we use a continuous real-vector for each word to represent similarity between words.
The idea of using a vector-space representation for words has been well exploited in the area of information retrieval …
将神经网络用于自然语言任务,NNLM不是首次尝试,而作为模型基础的单词的分布式表示(distributed representation)概念也不是NNLM首创,而是1980s年代NN短暂复兴时期的常见议题,主要推动者为NN开拓者Hinton,而直接引发当时复兴的BP算法文章(Rumelhart, Hinton, Williams 1986)主题就是用BP算法学习分布式表示。
NNLM的主要贡献是有效的结合了两者,通过共享的编码矩阵将“分布式表示”嵌入语言模型,关注点从Hinton所强调的通过学习分布式表示获取词语关系,转移到语言模型本身。在词向量(distributed feature vectors)基础之上,NNLM将语言模型拆解为词汇编码和任务处理两个阶段,经过训练同时获得词向量和语言序列的概率。最后,NNLM成功在大规模数据集上实现训练,并获得了超越传统统计语言模型的表现。
NNLM模型作为n-gram语言模型,相比传统统计语言模型,其参数量是词汇量|V|(以及窗口大小n)的线性函数,大大提升了多元模型(提取长程依赖)的可行性。文章中n取到5,超越了当时表现最好的3元语言模型(及其他传统5元模型),且无需传统模型对于概率的细致调整和平滑操作。模型的主要瓶颈在于输出层softmax的计算,这个问题在后来的Word2vec中得到较好处理,同时作者也清楚的意识到(静态的)词向量无法有效处理一词多义,这点要到十多年后的预训练模型(动态嵌入)才得以有效处理。
NNLM文章突出了单词的分布式表示作为连续空间实向量的优势,而经过训练后的编码矩阵可用于获得这种分布式表示(词向量)。并且作者在未来展望中指出可以探索词向量的具体内涵及潜在应用(Interpreting and possibly using the word feature representation learned by the neural network.)。此外文章还提到了可以将NN替换为RNN,进一步拓展可处理的序列长度,感觉NNLM这篇文章已经看透了语言模型后续的各个方向,实在厉害。而站在现在的视角来看,虽然NNLM将关注点从分布表示转向了语言模型,但确实却找到了获取词向量的正确方式,并直接启发了后续的Word2vec。而且将模型拆分为词汇编码和任务处理两个阶段,也与当下追求预训练模型的目标不谋而合。
在NNLM提出后有不少改进工作,主要围绕如何解决模型输出层的瓶颈。Bengio 原论文展望中提及了层级 (Hierarchical) Softmax 的设想,并在 2005 年发表了相关论文。2007 年 Mnih 和 Hinton 提出的 LBL (Log-Bilinear LM) 以及后续的一系列相关模型,省去了 NNLM 隐层的激活函数,直接把模型变成了一个线性变换,后来又引入层级Softmax进一步加速。2008 年 Collobert 和 Weston 提出的 SENNA (Semantic Extraction using a NN Architecture) 模型则是首个以生成词向量为目标的模型,不过为了提升运算效率,计算上未使用统计语言模型常用的条件概率,而直接将文本片段作为整体,替换中间词作为负例,模型输出为文本片段合理性的评分(单一数值),模型参数量和计算量大幅降低,但这也削弱了词向量的表征能力。2010 年 Mikolov 提出的 RNNLM 则主要是为了提升长程依赖提取(NNLM 论文已提及)。
Embedding
前面提到NNLM建立在单词的分布式表示之上,也就是今天所谓的词嵌入(Embedding),这是本文后续全部内容的基础,因此这里先对这个概念做个介绍。首先就是这个所谓的分布式(distributed)究竟是指什么?
在语言学/认知科学中,对于人类大脑中的概念 (concept/mental object) 一直存在两种观点:一种认为概念的内涵是通过相互间关系定义而非固有的(结构主义);另一种则认为概念可简单理解为一系列特征的集合。而对应到脑科学中,前一种观点认为每个概念对应大脑中一个(或少数几个)神经元,大脑皮层中的神经网络则对应概念间关联,当提及某个特定概念时只有少数脑细胞会激活(祖母细胞);后一观点则认为单个神经元对应于特征,而概念作为特征的集合,其编码需要大脑皮层特定区域神经元的集体参与,当提及特定概念整个区域都会激活,而区分概念的是具体的响应模式(不同神经元的参与情况)。基于上述特征,两种观点分别被称为概念的局部(localist)表示和分布式(distributed)表示。
站在今天视角看,人类对于大脑的认知还太少,这些类比解释大概率都比较片面。不过就数学上而言,前一理解中概念可对应为各自独立,且没有本质区别的独热编码,通过学习相互间关联来实现概念的区分;后一理解中概念则可对应于特征空间中的一个向量,也就是所谓的嵌入(Embedding)。在NN发展的早期,深受脑科学影响,因此也存在局部表示和分布式表示的探讨,现在看来其实两者都有其合理性。如果将神经网络输入层的嵌入矩阵单独拿出来,作为每个单词所对应的嵌入向量,确实更符合将“概念”作为特征集合的认知,“概念”之间通过共享底层特征相互关联。但是如果将神经网络视为整体,作为真正输入的其实是每个单词的独热编码,可视为正交的全同单元,本身并不具有任何意义,每个词语的真正内涵是通过神经网络所建立的词语间的相互连接所定义的,这又完全符合结构主义的认知——概念内涵是通过相互间关系定义而非固有。所以两种观念更多的还是视角问题,很难说有绝对的对错之分。
虽然分布式表示的名字源于脑科学的类比,但人类对于大脑的认知却并不足以为其效性/合理性背书(早期NN研究者似乎也并不在乎)。现在人们通常会将其理论依据归于早期的语言学假设:Harris 在1954年提出了语言的分布假说(distributional hypothesis),认为上下文相似的词其语义也相似(words have similar meaning if used in similar contexts);1957年Firth又将其阐释为词的语义由其上下文决定(a word is characterized by the company it keeps),并广为流传。这也是为什么在人工神经网络领域之外,利用传统统计方法,如信息检索领域的文本向量空间模型(Vector Space Model),获取的“词向量”会被称为基于分布(distributional)的表示,而非分布式(distributed)表示。不过随着NNLM的提出,新的词嵌入方法大多都选择基于人工神经网络,而非传统方法。
最后再强调一下,这种基于分布的词向量表示反映的是其常见的语境,而词向量的差值大致反映词语在句子中的相对位置情况。具体的,可以想象猫和狗的词向量应该是比较接近的,而北京或上海与中国在句子中的相对位置与东京或大阪等与日本在句子的相对位置接近,因此大概率有“北京 - 中国 ≈ 东京 - 日本”,类似的还有最常提及的例子“King - Man ≈ Queen - Woman”。又比如看到的一个有趣的例子“Oink - Pig + Cow ≈ Moos”, “Oink - Pig + Cat ≈ Miaowing”, “Oink - Pig + Dog ≈ Barks”都比较正常,而“Oink - Pig + Santa ≈ HO_HO_HO”就比较有趣了,最令人好奇的当然是What does the fox say? “Oink - Pig + Fox ≈ Phoebe”,显然狐狸叫声相关的语料并不足,单靠一首歌无法扭转这一现实😂️,模型已经无法获得有意义输出了。
单词嵌入
在NNLM文章指出了单词的分布式表示的优势后,后续研究逐渐意识到以词向量作为语言模型输入不仅能极大简化模型,减少计算量,且效果不错。并且从SENNA(2008)开始,研究者就着手尝试以词向量本身为目标,但可能是效果一直不理想(以及计算瓶颈),一直没引起太大关注。直至Word2vec(2013)出现,词嵌入才开始真正开始成为NLP领域的主流技术。此后陆续出现GloVe(2014)、fastText(2016)等改进的词嵌入算法,而将预训练词向量作为语言模型输入也成为业内默认做法,NLP预训练模型探索之路由此进入正轨。
Word2vec(2013)
Word2vec的代表作有两篇,第一篇文章1中作者给出了算法的两种实现方式(CBOW和Skip-gram),并基于前面提到的层级Softmax进行计算加速。第二篇文章2则主要是引入了替代层级Softmax 的负采样算法(Negative Sampling),以及二次采样(Subsampling)等如今较少讨论的速度优化技巧。
相比NNLM,Word2vec去掉了非线性隐藏层,仅使用两层神经网络,并将原本词向量的拼接操作替换为求平均(Skip-gram中连求平均也不需要),且同样没有非线性激活:将单词One-hot编码与嵌入矩阵相乘得到的词向量求平均后,直接交由输出层计算softmax概率。此外参考SENNA的做法,Word2vec同时利用上下文信息,并通过替换中间词构建负例。
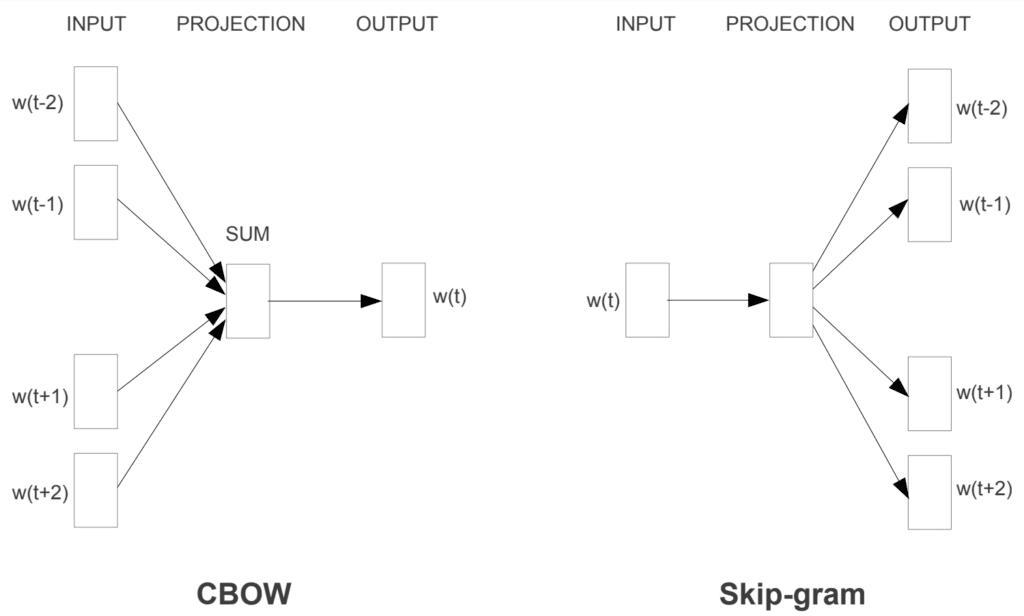
具体的,在实现上,CBOW是通过上下文预测中心词,而Skip-gram是通过中心词预测上下文(跟传统n-gram相对)。上下文信息加上求平均操作,CBOW完全抹除了输入的语序信息,与传统的Bag-of-Words做法一致,但又有别于传统语言模型,CBOW要获得是内容的连续分布式表示(continuous distributed representation),因此称之为CBOW(Continuous Bag-of-Words)。CBOW会对上下文平均,而Skip-gram则只能逐对(pairwise)单词训练(同样不关注词序),因此训练速度上CBOW更快,但在生僻字应对上不如Skip-gram。
取词库大小为|V|,词向量长度为D,非线性隐层单元数H,则在NNLM中词向量编码矩阵维度为|V|*D,n-gram模型词向量拼接后长度为(n-1)*D,到非线性隐层的变换矩阵维度为(n-1)*D*H,非线性隐层到输出的变换矩阵维度为H*|V|,最后还有词向量直接到输出的连接(绿色虚线),对应变换矩阵维度(n-1)*D*|V|,从而总参数量为(n*D+H)*|V| + (n-1)*D*H(未考虑偏置项)。虽然参数量是词库大小|V|和窗口大小n的线性函数,但依然是比较多的。在Word2vec中,去除非线性隐层和词向量的拼接操作后,模型简化为输入到隐层的变换矩阵(|V|*D)和隐层到输出的变换矩阵(D*|V|),总参数量仅2D*|V|(和窗口大小无关)。
这里到底是行向量还是列向量,以及维度是D|V|还是|V|D还需要确认????
h=Wx,W就是D*|V|;h=WTx,W就是|V|*D
注意,经过一系列简化后,除了参数量大大减少,Word2vec模型还出现某种“对称性”:输入层到隐藏层的变换矩阵W1为|V|*D,而隐藏层到输出层的变换矩阵W2为D*|V|。词向量编码矩阵W1中的列向量与单词一一对应,与单词One-hot编码相乘后,得到单词对应词向量(也就是W1的列向量)。而之后对应到特定单词的输出时,词向量要与W2中特定的行向量相乘,从而W2的行向量也是与单词一一对应的,也就是这里同时存在两个词向量编码矩阵。通常的做法两个词向量的编码各自独立,然后取平均作为最终输出,也可以保持两个词向量编码相同,不过实现上会相对复杂,但据说效果更好(source: CS224N)。
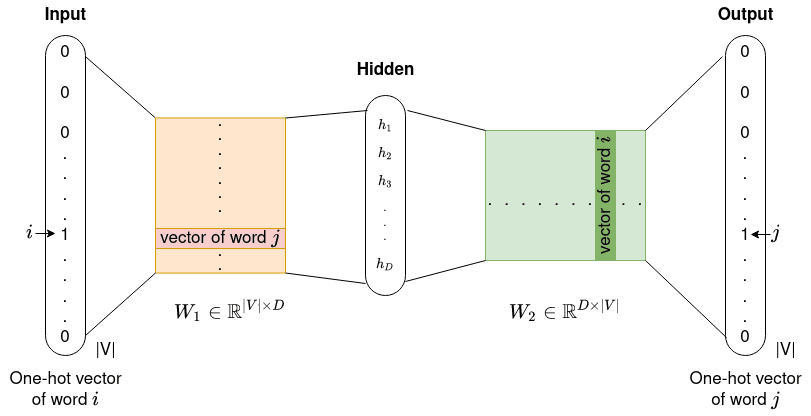
最后,基于上述分析,对于特定的输出,我们并不需要关注整个编码矩阵,而只需要关注输入词向量以及与输出对应的输出词向量,即输入softmax激活的可简化为,因此Word2vec损失中的softmax概率通常会表示为如下形式:
左侧为CBOW,为上下文词取平均后的输入词向量,而为输出词向量;右侧为Skip-gram,为输入词向量,而为输出词向量。这种表达形式不仅简洁,而且还很直观:基于前面提到的分布假说,词的语义由其上下文决定,对于CBOW就是用近似(虽然直接求平均的合理性存疑),而向量内积刚好在一定程度上反映了向量相似程度,因此最大化上述概率就对应使尽量靠近;Skip-gram则是对上下文的单词逐对执行类似操作,并最大化同时接近全部上下文的概率(),相比CBOW简单求平均似乎更合理。考虑到所有训练语料(概率相乘),最终优化目标就是最大化(对应交叉熵损失):
进行训练时,每步更新都需要对词库中所有单词计算sofmax概率值,而词库通常在十万、百万量级,为了减少softmax计算量,一般的策略是采用层级softmax:基于霍夫曼编码构造二叉树,将所有单词对应于二叉树的叶节点(深度~log2|V|),每个单词的softmax概率可由其路径上各节点的二分概率(sigmoid值)相乘得到。|V|分类问题被拆解为O(log2|V|)次的二分类问题,而且霍夫曼编码高频词路径短的特性有助于进一步提速。
具体的,在层级softmax中,上文中输出词向量的概念(|V|个)被替换为对应于二叉树内部节点的向量(不对应任何具体单词,|V|-1个)。每个节点走向其特定子节点的概率可由Sigmoid函数计算,而就对应另一子节点的概率。简单起见我们这里约定左侧子节点取正,右侧子节点取负(只要整个训练过程中保持固定就不影响)。最终取到某个特定单词的概率就决定于由根节点到达其对应叶节点的路径上一系列节点概率之积 ,其中node对应路径上节点,走向左侧子节点时取正,走向右侧子节点时取负(等价于文章中那个看似很复杂的表达式)。
最后,作者在噪声对比估计(Noise Contrastive Estimation, NCE)的启发下提出了更为简单高效的负采样(Negative Sampling)策略替代层次softmax。我们的期望是预测词与正确候选词尽量一致,最关键的是正确候选词softmax的计算,但概率归一化(以及参数的梯度更新)又要求必须有一定负例,因此可以在正确候选词之外,再随机选取一些单词作为负例,这就是所谓的负采样(也被称为候选采样)。使用采样后的softmax函数,每次只更新正确候选词及采样到的负例相关的参数权值,而由于是随机采样,理论上所有候选词相关的权值都可以得到更新。相比层级softmax,负采样只是一种近似的随机算法,但实际效果上通常不错,而且实现上更为简单,计算量也更低。
Word2vec相比NNLM大幅简化,特征提取的能力是否得以提升很难说,但正是在这一系列简化以及各种优化策略的加持下,Word2vec得以在远超之前规模的语料上训练,从而获得出色的词嵌入效果,并最终推动词嵌入在NLP领域普及。感觉这其中对于计算瓶颈的突破,叠加超大数据集的训练是真正的关键。
GloVe(2014)
这里沿用前面的符号,为单词的输入和输出(嵌入)向量,对应文章中的
Word2Vec词嵌入主要依赖局部信息(由窗口大小决定),GloVe考虑基于传统的共现矩阵考虑全局关联信息。同时为了避免softmax对全部单词计算指数运算,模型损失函数变为最小二乘:
- skip-gram损失为
- 利用共现次数可合并计算:
GloVe中共现次数有一个衰减系数,使距离越远的词对共现频率越小一些 - 其中需计算softmax进行归一,为减少运算量,GloVe选择不进行归一化,取,直接用最小二乘:
- 考虑到取值范围较大,选择取对数从而
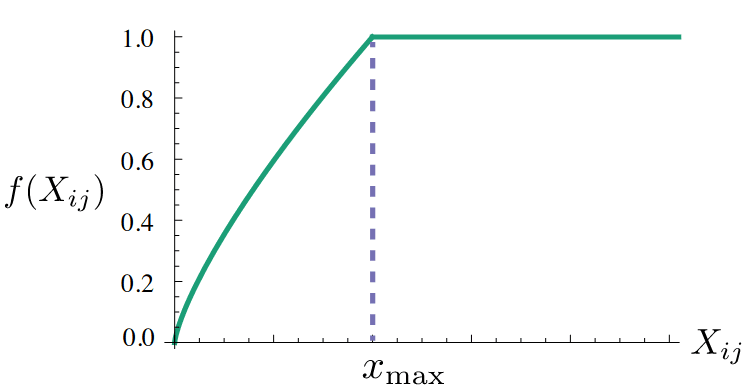
- 为压低虚词,当共现次数达到某个阈值后截断:
f(Xij) 是一个权重系数,主要目的是共现越多的 pair 对于目标函数贡献应该越大,但是又不能无限制增大,所以对共现频率过于大的 pair 限定最大值,以防训练的时候被这些频率过大的 pair 主导了整个目标函数。
 source: Pennington et al. 2014
source: Pennington et al. 2014 - 最后加上输入输出各自的偏置项就得到了上面损失函数的最终形式。
fastText(2016)
将单词拆分为子片段(n-gram character)或字母(character)是处理不常见词或OOV词的常见做法。fastText的思路就是将词片段(sub-word)信息引入word2vec,每个单词的词向量为其所有片段嵌入向量之和。具体的有两篇,分别介绍了基于BOW和Skip-gram的实现。
在实现上fastText并未考虑构词法(词根、词缀),而是固定字符数,进行重叠的切分,同时在单词首尾会引入额外标记<,>。以where为例:加上首尾标记<where>,取字符数n为3,对应片段有<wh, whe, her, ere, re>。实际中会考虑n取3到6的所有片段,此外还会额外加上单词本身<where>。假设为单词的n-gram片段,为片段的嵌入向量,则有词向量,相应的词向量内积。
计算上同样基于层次Softmax或负采样进行加速,而考虑到sub-word信息,虽然有Hash技巧降低内存占用,但相比word2vec应该还是更慢的。BOW文章的重点并非词嵌入,而是在文本分类任务(标签预测和情感分析)中的速度及精度;Skip-gram文章的重点是词嵌入,但没有对比速度,因此fastText中的fast指的应该是模型用于文本分类任务时速度快,而非词嵌入速度比word2vec等更快。在词嵌入上,fastText的主要优势在于,借助sub-word词片段的嵌入可以更好的处理OOV词的词向量问题。
Evaluation
有了不同词嵌入算法,如何对嵌入效果进行评估对比?最直接的想法是将得到的词向量用于实际任务,通过模型表现进行判断,但这种方式计算成本高,且模型子模块间通常存在复杂的关联耦合,于是人们发展了一些简单的专门任务用于评估。一种思路是计算相近词语嵌入向量的相关性(Correlation Evaluation):由人对单词的相关度打分,与词向量的余弦相似度对比。另一种做法则是类比评估(Analogy Evaluations),即上文提到的词嵌入例子,如北京之于中国相当于东京之于什么?计算基于词向量进行类推的正确率。
最后,将词向量用于具体任务时可进行针对性微调,但需要数据量足够大才有正面效果。数据量较少时,单词量相对少,词嵌入的空间将发生较大变化,最终模型训练效果可能反而变差。只有当嵌入的单词都被训练数据覆盖到时,才能实现微调,而非大幅变动。
句子嵌入
在词嵌入受到重视后,一个发展方向是词片段以及字符级的嵌入,另一个方向则是语句、段落乃至整篇文章的嵌入表示。相比词嵌入,句嵌入的主要优点在于嵌入向量已包含语序信息,有助于提升机器翻译、摘要总结、文本分类等依赖整句信息的下游任务表现。
Doc2Vec(2014)
Doc2Vec也被称为Paragraph Vector(PV),做法非常简单,直接在Word2Vec模型中引入一个新的句向量作为输入。如下图所示,左右两种做法分别被作者称为分布式记忆(PV-DM)和分布式词袋(PV-DBOW),对应于Word2Vec中的CBOW和Skip-gram算法。
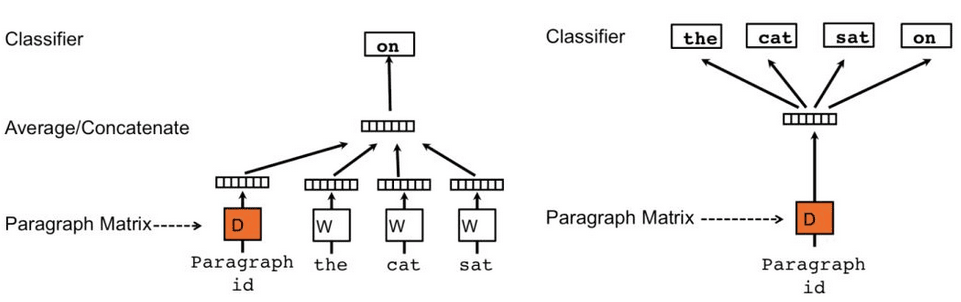
核心的区别在于多了一个句向量(橙色):句向量对于同一语句是共享的,不同语句间是独立的,词向量则在所有语料间共享。另一点不同是虽然PV-DM结构类似CBOW,但并不完全属于BOW,训练时会在句子上用滑窗选取片段,并始终用前面的单词预测后面单词,而PV-DBOW则与SKip-gram一样,完全不考虑语序。实践中,PV-DM效果通常要比PV-DBOW好(因为前者部分考虑了语序?),但两者结合的效果通常是更好的。
Doc2Vec的先天缺陷其将句向量视为与词向量平级的输入,而非关于词向量的某种函数。但句子的多样性要远多于单词,句向量并不像词向量那样具有通用性。测试的句子与训练数据总是不同的,也就意味着训练时学习到的句向量在测试时是无法使用的。测试时需要保持词向量及其他模型参数不变,从头学习句向量,再用于后续任务。
Skip-thoughts(2015)
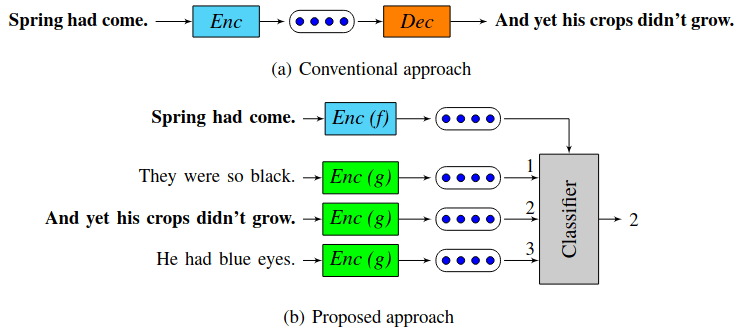
相比Doc2Vec在Word2vec基础上引入句向量,同时训练词向量与句向量,Skip-thoughts则是直接将Word2vec的思路由单词推广到句子层次。模型采用编码器-解码器/Seq2Seq结构,将句子作为输入输出的单位,由输入语句预测其上文及下文的句子,如下图所示。

Skip-thoughts应该是句嵌入中最经典的工作,但其缺点在于这种序列生成任务训练太慢,此后的工作在主要集中在提升速度方面。
构建通用句嵌入的范式,确定了大规模预训练语言模型的方向。
并且基于当时已提出的(互)注意力机制可实现动态嵌入。The source sentence representation can also dynamically change through the use of an attention mechanism to take into account only the relevant words for translation at any given time.
SDAEs & FastSent(2016)
Hill等人提出了序列去噪自编码器(Sequential Denoising Autoencoders, SDAEs)和FastSent两种无监督的句嵌入方法。前者随机删除序列中的单词,并随机互换相邻单词(对不重叠的二元组操作,保证是相邻单词),之后将破坏后的序列输入类似Skip-thoughts的Seq2Seq结构中,目标是还原引入破坏前的语句。后者则是Skip-thoughts的词袋简化版,即不考虑语序,由输入语句的所有单词预测上下句的所有单词。句子嵌入取为序列中所有单词的词嵌入之和:设为单词的输入和输出嵌入,代表语句,其句嵌入。训练的损失函数相应简化为(为softmax函数)。模型简化后,没有了RNN的时序限制,表示能力有所下降但训练速度得到极大提升。
InferSent(2017)
同样是学习通用的句嵌入表示,InferSent是继续沿着有监督学习的路线探索,并取得了超越Skip-thoughts的效果。在尝试了不同任务后,作者认为自然语言推理(NLI)是有监督学习句子通用表示的最佳选择。NLI本质上是一个分类任务,模型需要判断两个输入语句的关系,有蕴含、矛盾或中立三种可能。而编码器的选择上,作者也进行了多种尝试,包括层次卷积、循环网络、自注意力网络等,最终双向LSTM+最大池化取得了最佳效果,不仅超越了Skip-thoughts等无监督学习,而且训练也更快。
Quick-thoughts(2018)
受Skip-thougths及语句排序任务启发,Jernite et al. (2017)提出了基于语句连贯性实现的几种无监督训练方法:判断相邻句对的先后顺序、从候选语句中选择下一句以及判断两句话之间的承接关系,实现了更快的句嵌入。而受上述工作启发,Logeswaran & Lee 提出了Skip-thoughts的加速版Quick-thoughts,将原本的困难耗时的生成任务改为分类任务:将目标语句的正确上下文与负例一起编码,并让模型从全部候选语句中挑选正确的上下文。最终模型训练速度提升一个量级的同时,获得了比之前更好的效果。
本质上,quick-thoughts就是句子层面的word2vec(skip-grams):后者输入是单词,目标是找出上下文单词;前者是输入句子,目标是找出上下文句子,而加入的负例句子刚好对应word2vec的负采样加速算法。将句子替换为单词,编码器简化为词嵌入表,前者自动退化为后者。需注意的是,虽未采用Seq2Seq结构,只需用到编码器,但quick-thoughts中有参数独立的两个编码器,分别处理输入语句及待分类语句,而不是用同一个编码器处理。这点与word2vec中有输入和输出两组嵌入编码是一致的,但感觉其实没有必要,两个编码器参数共享应该是更好的选择。
USE / GenSen(2018)
通用句编码器(Universal Sentence Encoder, USE)提供了两种编码器结构,分别基于Transformer和深度平均网络(Deep Averaging Network):前者使用Transformer的编码器,后者使用DAN,并同时考虑词以及词对(bi-gram)嵌入,将词及词对嵌入平均求和后,传递给深度前馈网络计算句嵌入。前者精度高,但模型更复杂,训练也更耗资源(内存、时间),后者模型简单、速度更快,但精度略差。
对于训练任务,Skip-thoughts说无监督更通用,InferSent说有监督也不差,USE则说:“我全都要!”训练时采用多任务学习,既有Skip-thoughts等采用的无监督学习,也有文本对话和文本分类等有监督学习。多任务学习并非新概念,在上个世纪已被提出(Caruana 1993),词嵌入被提出后,Collobert & Weston 2008 就曾尝试将多任务学习应用于 NLP 领域,将词嵌入矩阵在不同任务间共享,同步训练,提升词嵌入的泛化能力。而相比共享词向量,USE中共享的是全部模型参数。
GenSen的卖点同样是通过多任务训练学习通用句表示,任务相比USE更丰富,包括多语言机器翻译、文本分类/自然语言推理、句法分析以及类似Skip-thoughts的上下句预测。网络结构与Skip-thoughts基本一致,编码器为双向RNN,解码会根据具体任务选择单向RNN或分类器。arXiv上只比USE晚一天发布,所以是独立工作。
动态嵌入
句嵌入虽然在很多下游任务上取得了不错表现,但很快就走到了尽头。早在2014年提出的注意力机制(Bahdanau et al. 2014)就已指出将任意长度文本压缩为固定长度向量的做法,所能保持的信息量有限,而随着句子长度增加,信息损失也将越严重。与此同时为解决词嵌入的问题 [之后随着注意力机制逐渐受到重视?],词嵌入也终于迎来了下一个阶段——动态嵌入或者说基于语境的嵌入(Contextual word representation),预训练语言模型随之开始涌现。而最终的突破则是随着2017年Transformer(Vaswani et al. 2017)的提出,LSTM被自注意力机制所取代,大规模语言模型的并行训练成为现实。
注意力机制NLP基本概念II中介绍。
Context2Vec(2016)
虽然词嵌入为NLP领域带来巨大进步,但早在Bengio最初提出NNLM模型时就已指出其先天缺陷:将单词对应于单个向量无法处理多义词。而多义词在自然语言中是非常普遍的,比如可以说湖水很深,也可以说某件事水很深,其含义是相关但又不同的。甚至有些语句对于人类而言都是存在歧义的,此外还存在各种代词,本身并没有具体含义,专用于指代各种概念。这类词义消歧(Word Sense Disambiguation, WSD)、命名实体识别(Named Entity Recognition, NER)、指代消解问题(Co-reference Resolution)等问题仅靠不考虑语境的静态词嵌入是无法处理的,需要能真正反映词语多义性的嵌入。
早期的尝试并没有摆脱静态嵌入的定式,主要是通过聚类或WordNet等辅助信息对单词含义进行分类,对每个类别分别获取对应的静态嵌入。更好的办法是将单词的上下文信息融入词向量,最简单的是对单词附近窗口内词嵌入求平均或加权求和等,更进一步的会在具体的NER、指代消解等任务中监督学习如何整合单词附近窗口内词嵌入。Context2Vec沿着这一思路继续推广,并参考word2vec,通过无监督的语言模型学习如何对目标单词附近窗口内词嵌入的有效整合,以获取任务无关的上下文依赖词嵌入。
其本质其实非常简单,RNN网络的隐状态通常被理解为整个输入序列的语义编码,所对应的就是上节讲的句子嵌入;但从另一角度,也可将其理解为在给定上文语境下当前单词的语义编码。基于后一种理解,为解决RNN的隐状态包含上文信息的问题可引入双向RNN:使用两个独立的RNN,分别由前向后和由后向前读取序列计算隐状态,之后将两者隐状态拼接在一起作为最终语义编码,而这个语义编码综合了上下文语境信息,可作为单词的动态嵌入或语境向量。
双向RNN/LSTM在当时(2016)已不新鲜,Context2Vec的创新之处在于没有将其用于序列生成或其它监督任务,而是以输出上述语义编码为模型目标,用于获取语境向量。具体的如下图所示Context2Vec将双向LSTM与目标词(submitted)位置对应的隐状态输入MLP解码,之后与目标词对比计算损失,。
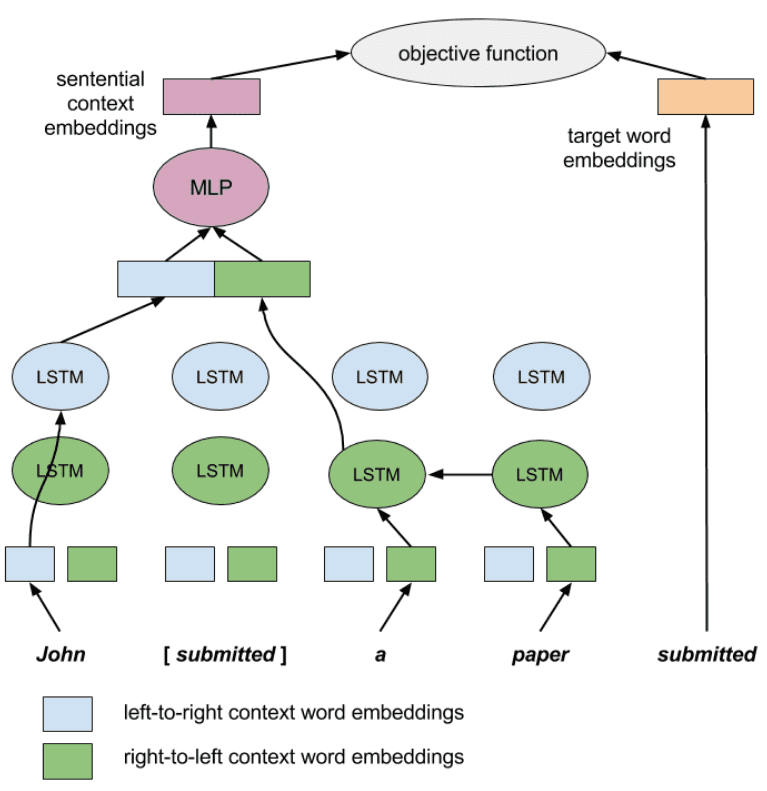
Context2Vec的损失与word2vec完全相同,由上下文预测中间单词,且同样采用负采样加速计算。不同之处在于这里的输出端和输入端向量不再“对称”:前者是目标词的(静态)词向量,后者则是目标词的语境向量。这种区别源于是模型本身的不对称,输入端(编码器)不再是简单的线性投影,由词袋变为考虑语序的双向LSTM,同时窗口也更大,可处理整个序列。这其实与Skip-thoughts的编码器是相同的,不同之处在于这里输出是单个词而非句子(未使用Seq2Seq结构),相对应的训练后编码器输出的是单词的语境嵌入而非句嵌入,此外不同于通常双向LSTM,此处目标词对应的隐状态是没有考虑目标词本身的,而只考虑了上下文(与CBOW相同)。
TagLM / CoVe(2017)
TagLM与CoVe是2017年的两个工作,前者侧重于将语言模型训练的网络用于具体的序列标注任务,后者则从更基础的NLP迁移学习的角度思考,这里主要介绍后者。
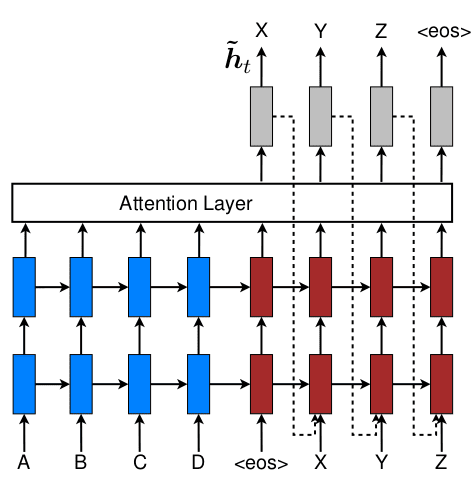
基于卷积网络在ImageNet上预训练的成功表现,人们开始尝试建立NLP领域的预训练模型,McCann等人认为在机器翻译任务中训练的LSTM网络非常有潜力,并由此提出了语境向量模型(Context Vector, CoVe)。具体的,模型编码器采用2层的双向LSTM网络,首先在机器翻译任务中预训练,训练后将编码器输出的隐状态作为语境向量;用于下游任务时,将输入序列的词向量和语境向量同时提供给任务模型。
CoVe主要受Skip-thoughts和注意力机制的启发,虽然基于Seq2Seq结构进行预训练(翻译任务),但模型未局限于Seq2Seq结构,试图将整个输入序列压缩为句向量,而是选择对每个单词(token)的词向量输出相应的语境向量(CoVe)。同样作为通用特征提取器,不同于Skip-thoughts等句嵌入,CoVe不关注句向量,回归了单词层级。
最后,虽然站在了迁移学习的高度,但CoVe与之前的Context2Vec(及TagLM)本质上一样,都是考虑用双向LSTM的隐状态作为语境向量。从注意力机制的角度理解,就是解码器去“注意”的那个编码器隐状态,非常合理(具体可参考NLP基本概念II中对注意力机制的介绍)。CoVe与Context2Vec(及TagLM)的核心区别在于训练任务,不过所选的机器翻译任务相比无监督的语言模型可以说是开倒车,此外LSTM更深(2层),并直接以GloVe词向量作为输入。另一点需要注意的是,Context2Vec及TagLM中所用的其实并不算真正的双向RNN,Context2Vec中输出隐状态未考虑了目标词本身,TagLM中则是分别用语言模型训练两个单向RNN,预训练后才拼接隐状态用于下游任务,这点在ELMo中具体讨论。
ELMo / ULMFiT(2018)
ELMo和ULMFiT是同时期的两个工作,ELMo稍早,ULMFiT引用了前者。两者都选择回归无监督的语言模型作为训练任务(而非CoVe所选择的监督任务),都采用了多层LSTM(2层和3层)的双向语言模型作为编码器,前者重在动态嵌入,后者重在迁移微调,下面分别介绍。
需要强调的是由于基于语言模型进行训练,ELMo及ULMFiT中的双向语言模型与CoVe中的双向RNN并不同。
- Context2Vec中为避免信息泄露,不同于通常双向RNN,输入没有考虑要预测的词,即由上下文预测中心词,属于掩码操作。双侧但掩码
- TagLM中虽然序列标注任务所使用的是2层双向RNN,但生成语境的两个RNN(单层)是分别基于语言模型进行训练的。单侧信息
- CoVe中是正常的双向RNN,不过其训练任务为机器翻译,双向RNN仅用于编码器,不涉及语言生成,不存在信息泄露。生成任务有单向RNN的解码器完成
- ELMo中的双向RNN其实是两个独立的多层单向RNN,分别基于语言模型训练(损失加一起),预训练后才将每层隐状态拼接用于产生语境向量,ULMFiT中也是类似操作。
也正因如此,TagLM、ELMo、ULMFiT都将其成为双向语言模型而非双向RNN。
除此之外,ELMo相比CoVe(以及Context2Vec, ULMFiT等)的主要区别在于,对每个输入序列单词,选择将所有层LSTM的隐状态整合为一个向量,而非仅考虑最后一层:
式中用于标识输入单词(token),为网络层数,为单词所对应的层(隐)状态(对应输入词向量)。和为下游任务确定的权重参数:其中有点类似注意力机制中的权重项(softmax归一化),只是这里是对特定单词的所有层进行整合,而非对最后一层的所有单词进行整合;是整体缩放因子,在目标任务与预训练任务差别较大时,该参数有助于模型优化。权重虽然是softmax归一化的,但并不像注意力机制依赖于(具体可参考源码scalar_mix),因此相当于在预训练模型的所有层与下游任务之间插入了一个线性层(且所有输入单词间参数共享),用于下游任务时,冻结预训练模型参数,对线性层进行微调。
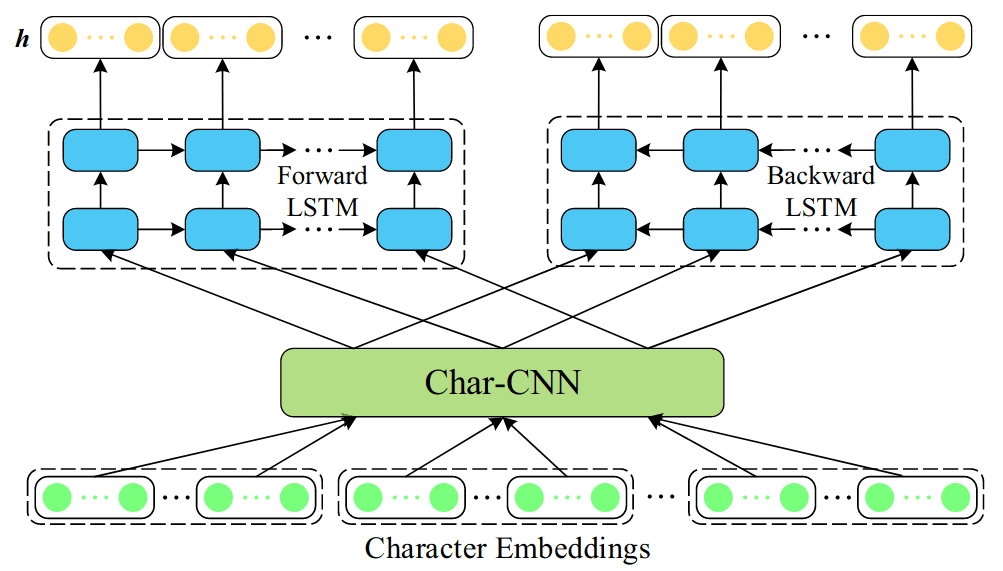
ELMo的具体结构如下左图所示,为2层的双向语言模型(加上残差连接),输入未使用词嵌入,而是字符级嵌入,由Char-CNN处理后,传递给LSTM网络。Char-CNN的结构如右图所示,由CNN和highway层组成,具体可参考Kim et al. (2015)。基于字符嵌入的模型能减少模型参数(词库缩减为字符库)、缓解OOV词问题,可处理训练语料未包含的单词。
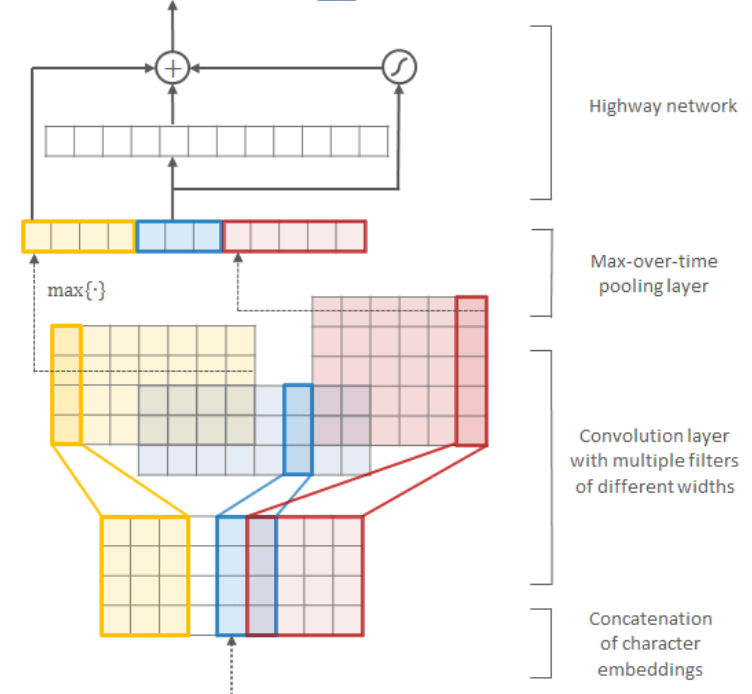
对于深度网络,通常认为随着网络层的加深,提取到的特征也更加顶层和具有针对性,浅层特征的则通常更为底层和通用,因此CV中微调时通常会冻结网络的浅层,只调整最后一层或几层。但(当时)NLP领域的网络通常很浅(2~3层),直接微调很容易破坏预训练结果,即所谓的灾难性遗忘(catastrophic forgetting)问题。
ELMo的做法在通用预料上预训练后,会先在目标任务语料上训练一个epoch,之后用于具体任务时与前面的TagLM、CoVe等相同,冻结模型,将其输出的语境向量和词向量一起提供给下游任务。所不同的是ELMo中语境向量本身是可微调的,如前面所说,相当于在预训练模型的所有层与下游任务之间插入了一个线性层。
ULMFiT中语言模型在通用语料上预训练后,同样先使用目标任务语料微调,之后会针对目标(分类)任务进一步微调。而为更好的实现微调,ULMFiT提出了区别性微调(discriminative finetuning)和斜三角学习率(slanted triangular learning rates)以及渐进解冻(gradual unfreezing)三种技巧:区别性微调是指在微调时对不同网络层设置不同学习率(区别对待),浅层学习率更小,调整幅度更小;斜三角学习率则是学习率先增后减,类似warmup操作,初始部分的小学习率可避免在微调起始阶段,模型不稳定时,预训练的参数遭到破坏(产生较大偏离);渐进解冻则是从最后一层开始逐层解冻(允许参数更新),每经过一个训练epoch追加一层解冻,直至第一层。其中区别性微调和斜三角学习率会在两步微调中都使用,而渐进解冻仅用于后一步微调。
虽然ULMFiT、ELMo在Transformer之后提出,但都还沿用了LSTM结构,但人们很快便注意到Transformer结构的优越性,尤其是对于大型的语言模型,因此之后的主流模型都转向了后者,如GPT、BERT,这期间ELMo原作者也给出了基于Transformer(及CNN)的变种。ELMo与之前模型的主要区别为:1.以字符嵌入加CNN网络作为输入(非首创),2.整合所有隐层作为语境向量,最终在多项NLP任务中取得SOTA成绩。ULMFiT关注点则在迁移学习的微调技术,模型相对简单,只用了基础的3层LSTM,未用注意力机制、快捷连接等技巧,也没有参考ELMo综合所有层隐状态,最终任务只测试了文本分类。因此ULMFiT热度远不及ELMo,当然ELMo名字取的也好(少儿节目芝麻街角色),与之后的BERT同属一个“宇宙”。
最后,到目前为止、对动态嵌入的理解都是站在单词层次理解,即模型目标是由上下文预测中间词。但其实损失是考虑了序列中所有单词的(对求和),因此同样可以站在序列层次理解:模型目标是由输入序列还原输入序列,这就是自编码器呀!具体的Context2Vec和ELMo中稍有区别之处在于预测每个词时的输入都有所不同,会对预测词掩码,TagLM和ULMFiT则不存在该问题(CoVe是有监督的所以不是自编码),预测每个词时输出的都是完整序列,从全部单词角度看,就是由输入序列还原输入序列。另一方面,虽然是序列到序列,但由于词语是一一对应的(N-to-N),因此并不需要Seq2Seq结构,只需要输出相比输入向后错一位就可由预测后续。
Recurrent neural network based language model. (Mikolov et al. 2010)
而其实基于Seq2Seq的自编码器也是存在的。文章中也得到提到了只保留编码器(或解码器)的语言模型训练
这点在下面ELMo的结构图中体现的更为清晰,且在BERT变种中还会讨论。
稍有不同的是这里将输出视为逐个的单词,类似于输入是语言序列,输出则是对应的词袋。
language model v.s. autoencoder
这种关联性将后面的预训练模型中进一步讨论
这点在GPT中最终得以完全体
BERT则又回归了Mask的方案
GPT / BERT(2018)
2017年用于机器翻译任务的Transformer模型率先抛弃传统的RNN与CNN,完全基于注意力机制实现,此后自注意力的概念普及,而自注意力基于Query整合上下文Value的操作非常适合语境向量的提取,具体可参考NLP基本概念II对自注意及IV对Transformer的介绍。
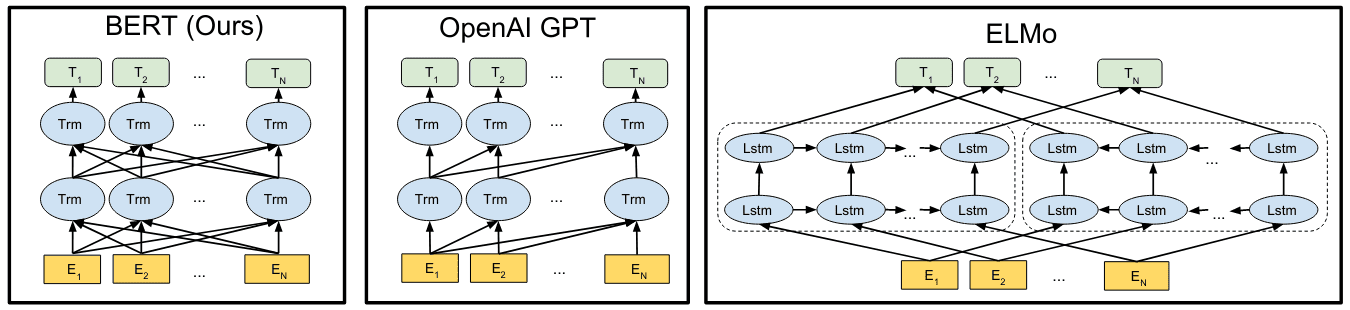
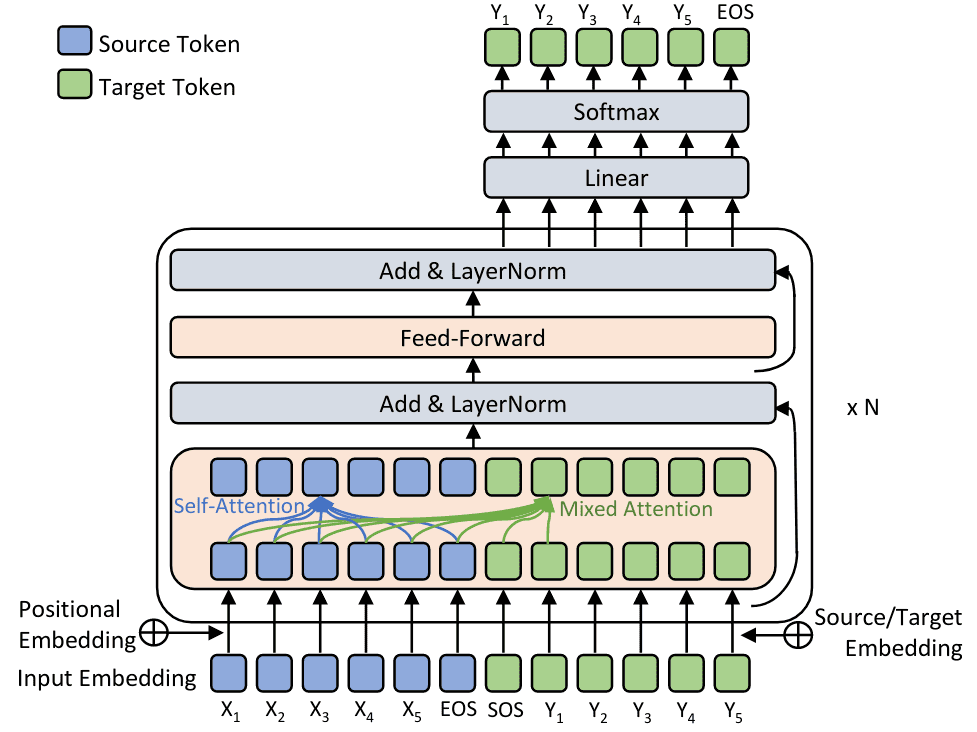
GPT和BERT都建立在Transformer之上,GPT中将翻译任务替换为语言模型用于实现无监督的预训练,而Transformer的Seq2Seq结构用于语言模型时,只需保留解码器即可。之所以不是编码器,是因为为避免语言模型训练过程中信息的泄露,必须用单向的自注意力机制(masked self-attention)。BERT则是在GPT基础之上考虑如何使用双向自注意力机制,以获取更全面的语义信息,为此BERT选择将语言模型任务替换为掩码语言模型(Masked LM),以解决信息泄露问题。最终,GPT采用单向自注意力,对应Transformer的解码器;BERT采用双向自注意力,对应Transformer的编码器。具体的,GPT、BERT及ELMo的区别可参考下图:
从最初的静态词嵌入到句嵌入以及动态嵌入,自然语言模型预训练和迁移学习逐渐成为现实,其中的核心问题是如何进行模型的训练和迁移。训练上有选择无监督的语言模型、语序判断、降噪自编码等,也有选择有监督的机器翻译或自然语言推理等;迁移上又有特征提取、模型微调两种做法。
在训练上,有监督的预训练受限于标签数据的获取,无监督训练无疑是更合理的选择,但由于在具体任务中两者实际效果各有胜负,无监督并未能表现出压倒性优势,因此有监督策略也一直没有被放弃。而随着GPT和BERT的出现,语言模型开始迅速的大型化,参数量从GPT的1亿(110M)、BERT的3亿(340M),到GPT-2的15亿(1.5B),一直到Switch-C的万亿(1.6T),一路飙升,而无监督训练(自监督学习)庞大数据量的优势也真正得以凸显。
在迁移上,特征提取是指处理任务时,将预训练模型冻结,仅作为特征提取器,为下游任务提供辅助的输入特征,每个下游任务依然需要训练针对性的复杂模型。相比之下,在预训练模型之上引入极小化的任务层,并对整个模型进行针对性微调的策略,无疑是更好的选择。但正如前面所讲,NLP领域的网络通常很浅(2~3层),直接微调很容易破坏预训练结果,存在所谓的灾难性遗忘(catastrophic forgetting)问题。因此从最初的word2vec一直到ELMo都是特征提取策略,虽然ELMo的语境向量会根据任务调整,但其预训练模型本身依然是冻结的。而在模型微调方向,早期的序列自编码(SeqAE, Dai & Le 2015)是对每个任务的语料数据单独的无监督预训练,作为后续任务模型的初始化。后来的ULMFiT选择先在大规模通用语料上预训练,之后在任务语料上微调训练,最后再针对任务优化,而为实现微调ULMFiT提出了区别性微调、斜三角学习率以及渐进解冻等训练策略,获得了不错效果,不过ULMFiT中仅处理了语言分类任务。
GPT中,在模型微调上选择将ULMFiT的两步微调合并,仅在预训练模型之上额外添加针对具体任务的输出层(线性投影+Softmax),并取整体损失取为任务语料上的语言模型损失及目标任务损失之和。而为了适应不同的下游任务,处理阅读理解、自然语言推理等同时涉及多个输入文本的问题,GPT提出了一种输入变换策略,基本思路是将成对的输入拼接为单一文本序列,中间插入分隔符。具体的,针对不同任务需要做不同处理,如下图所示:对于普通文本分类任务正常处理即可;对于语言推理任务NLI将推理前提与待判断假设进行拼接;对于文本相似性问题直接将两个文本拼接,考虑到GPT中模型是单向的,因此需分别进行两种拼接,输出相加后再投影;对于问答选择/阅读理解等多选问题,则将原文与所有待选答案分别拼接,模型输出投影后,交由Softmax输出各自概率(感觉将原文与所有待选答案拼接为一个序列应该也是可行)。
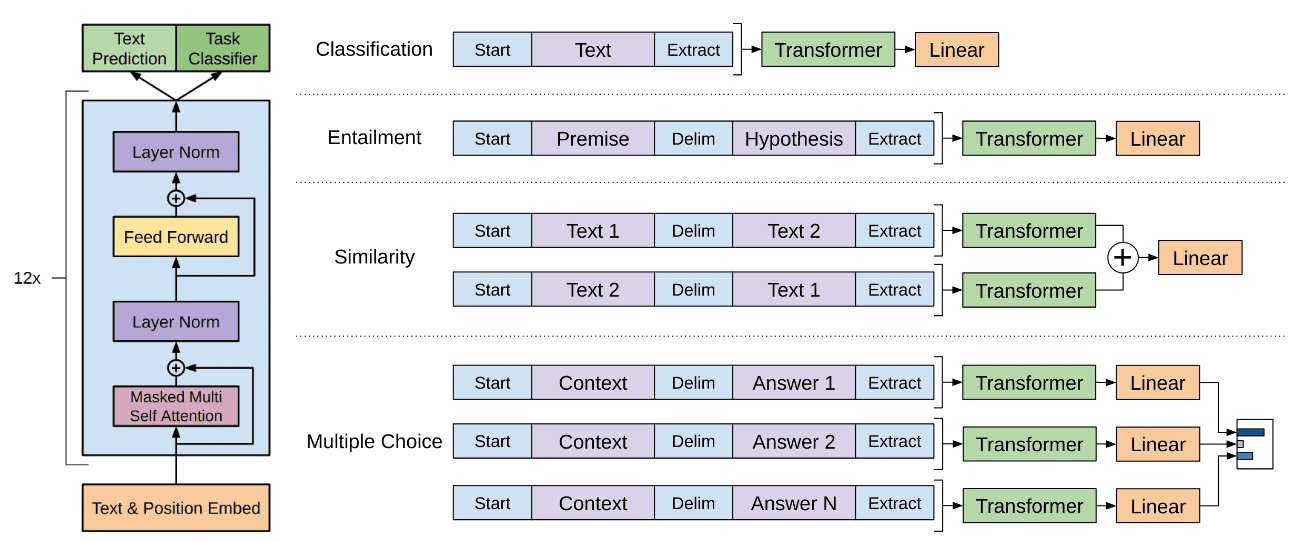
输入变换的出发点是用统一的预训练模型处理各种下游任务,最小化预训练模型所需的改动。在需要同时考虑多个输入文本的任务中,如果不进行拼接操作,就需要单独处理每个输入文本,但不同文本的地位并不是平等的,比如语言推理中的推理前提与待判断假设,阅读理解中的原文与待选答案,此时简单的线性投影+Softmax并不足以处理下游任务,需要针对不同任务引入分类器/解码器。而对输入进行拼接处理后,各种下游任务都可由线性投影+Softmax处理,额外参数只有线性投影的矩阵(以及拼接分隔符),简而言之就是任务去适配模型,而非模型去适配任务。
这种输入拼接的做法很有趣,是受之前Rocktaschel et al. 2015工作的启发,不过在该文章中是将网络视为两个LSTM的拼接,而非整体视为单个网络。相对应的,其所使用的注意力机制是互注意力,而非自注意力:权重连接只存在于句子间,句子内部没有连接。GPT则是打破了这种双网络的视角,将其视为整体,注意力机制也相应变为自注意力。
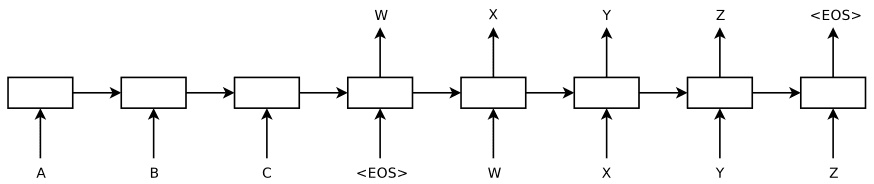
其实如果往回看,最初的Seq2Seq也是可以看到这种拼接的影子。如下左图所示,只需要打破编码器/解码器的视角,将左右部分视为整体,输入就是两个序列的拼接,<EOS>对应于分隔符。在引入注意力机制之后也依然可以从这一视角理解。
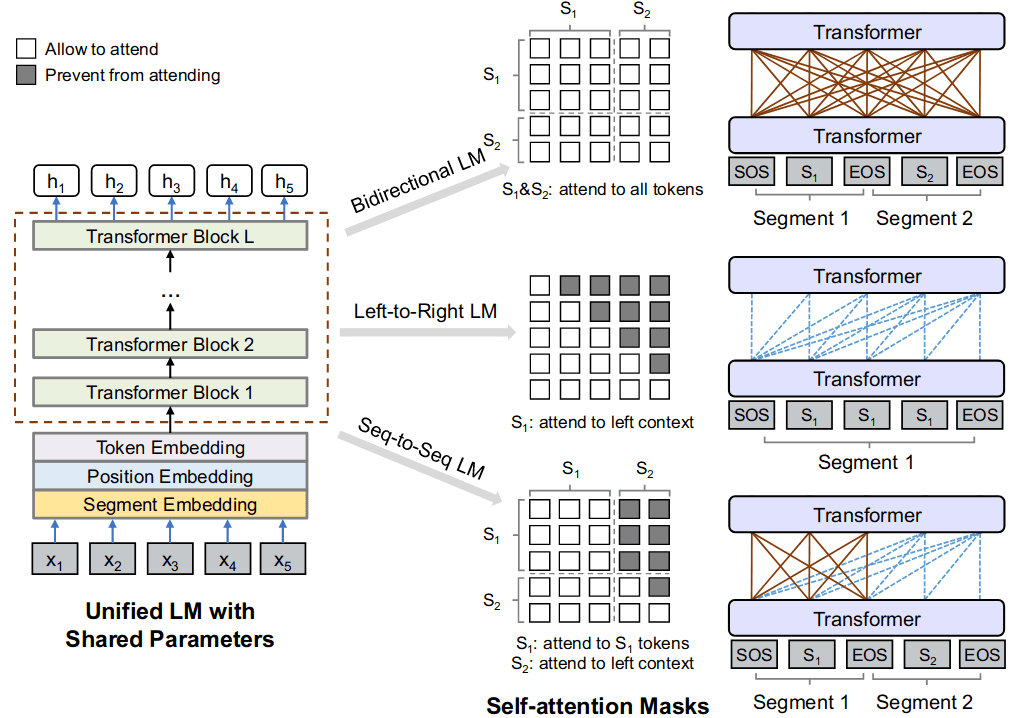
在Transformer中,同样有工作尝试将编码器与解码器融合,在He et al. 2018中作者就提出了将Transformer的编码器解码器逐层对齐(Layer Wise Coordination)的结构。虽然文章沿用了编码器解码器的视角,但只需要改变注意力的Mask矩阵,同样可将两者视为整体,而之后的UniLM中也确实是这样做的,通过调整注意力的Mask矩阵,将单向注意力、双向注意力用同一个网络实现,在自然语言的理解与生成任务之间共享模型。
从最初的单个RNN网路,到seq2seq中拼接两个RNN分别用作编码器与解码器,在机器翻译等条件语言模型领域获得突破,再到UniLM中将编码器解码器重新统一,NLP任务的网络结构经历了一个循环。至于这种做法与Seq2Seq相比那个更好,还是要看实践效果。
而为实现通用,除了输出层还需要对不同任务的输入做简单调整以使其适应模型,随着模型巨大化,这种方式相比反过来调整模型适应任务无疑是更合理的选择,在之后的预训练模型中得到广泛应用,并由最近出现的提示(prompting)策略进一步发扬光大。
GPT在网络结构和训练上没有太多创新,结构上使用了Transformer解码器,训练上则选择了无监督的语言模型。其主要贡献在于:针对训练,展现了无监督预训练(语言模型)的压倒性优势,引领了之后预训练语言模型的发展;针对迁移,引入了一种适应不同下游任务的输入变换策略,增强了模型的通用性。而紧随其后的BERT主要贡献在于通过引入掩码语言模型,将单向自注意力机制替换为学习能力更强的双向自注意力机制,进一步提升模型的语言理解能力,增强预训练的优势,同时也进一步拓展了GPT中的输入变换策略。
无论ELMo还是GPT,受语言模型本身的限制,动态嵌入/预训练都未能真正考虑双向信息。ELMo中的双向语言模型本质上是两个单向语言模型预训练之后的拼接,而GPT则只考虑了单向语言模型,这在一定程度上限制了模型的学习能力。反观word2vec等传统的词嵌入却可以真正同时考虑上下文,最初的Context2Vec沿用word2vec的思路,由上下文预测中间词,同样同时考虑了上下文信息。
为了在预训练中引入双向自注意力机制,BERT沿用了相同的思路:遮蔽某些词的信息,由上下文预测中心词,被称为掩码语言模型(Masked LM, MLM)。具体的,BERT会随机选择15%的词做MASK处理,由模型预测相应词。而考虑到预训练之后用于具体任务时并不存在掩码,为减缓这种训练与应用的不一致,对选中的词,BERT并不会全部MASK,而是80%的概率替换为[MASK]标记,另外各取10%分别替换为随机单词和保持不变。作者对不同掩码策略进行了测试,比如全部掩码、全部随机替换、80%掩码20%不变等,发现结果其实差别不大,除了随机替换占比较多时表现不太好,而整体上80%,10%,10%是相对合理的选择。考虑到MLM只预测了15%的词,而语言模型是每个词都预测,前者收敛相对慢,但即使未收敛,考虑双向信息的MLM表现就已超过了单向模型。最后,虽然这里说的是“词”,但其实BERT使用了sub-word技术,词会被进一步分为词片段(tokenize),所有的掩码操作都是针对词片段(token),而非完整单词的。
除了单词层面的训练,为使模型获取整句关系信息,BERT同时引入了另一个延续自quick-thoughts的任务:输入两个句子,判断是否为前后语句(Next Sentence Prediction, NSP);训练时会取50%输入为相邻前后句,50%为随机选取的两个语句。预训练时,MLM与NSP两个任务是同时/联合学习的,因此模型输入始终是两个拼接的语句,其中有随机MASK。而为了使模型在预测MASK单词的同时输出前后句判断,BERT在输入序列中引入了额外的[CLS]标记,将[CLS]所对应的输出向量专用于NSP任务,最终整体如下图所示。需要注意[CLS]的嵌入向量在预训练时用于NSP任务,不经过微调,在下游分类任务中并不能给出有意义结果。
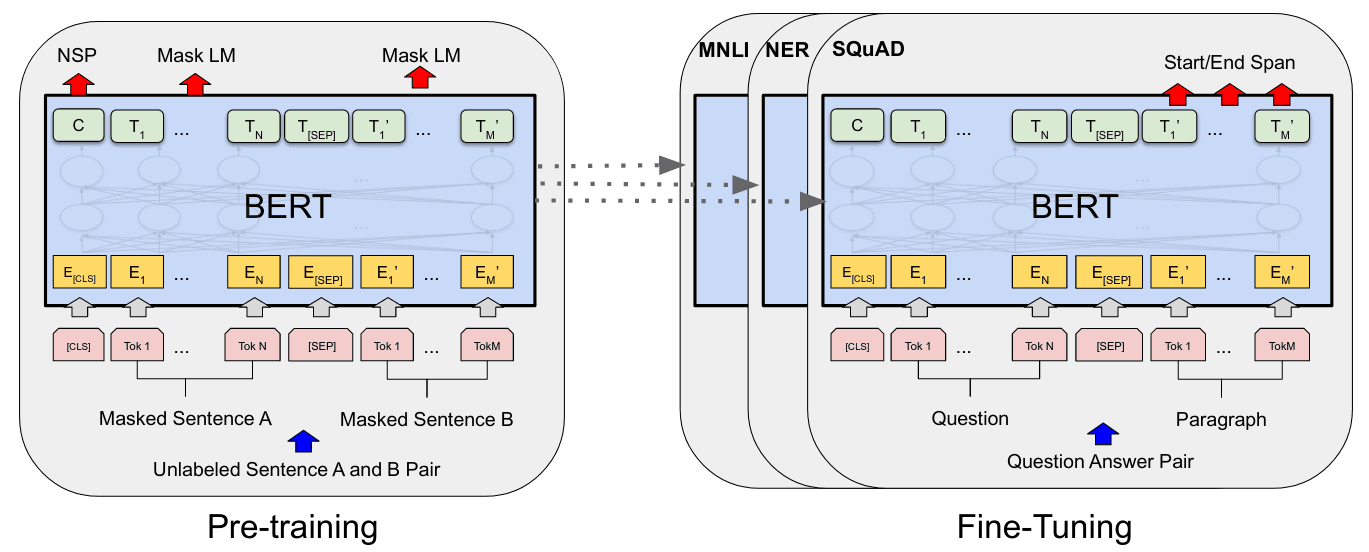
作为对比,GPT中句子拼接,只发生在预训练之后用于具体任务时,有起始、结束和分隔符三个标记。而BERT则是在与训练阶段就进行句子拼接,没有起始和终止标记,只有分隔符标记。同时为处理NSP任务,引入了额外的[CLS]标记,该标记所对应的最终隐状态用于句子分类任务。预训练后,用于下游任务时,根据具体任务:输入为单个语句或句子对,输出层考虑所有token对应输出或仅[CLS]所对应输出。这点除了[CLS]对应的额外嵌入外,与GPT没有根本性区别。值得一提的是,由于使用了双向自注意力,在处理句子相似性问题时,BERT并不需要像GPT中同时考虑两种拼接方式。
GPT中专门检验了移除NSP任务对模型在 NLI, SQuAD 等语句理解任务上表现的影响,发现确实有明显下降。不过之后的 RoBERTa 指出如果移除NSP任务的同时,放弃预训练阶段的句子拼接,最终模型效果并不会变差。事实上,相同的输入长度,不拼接可提供更长的连续文本,从而使模型捕获更长程的关联,最终表现上反而有小幅提升。不过MLM以及NSP确实打开了自监督训练的思路,此后很多工作在这方面进行拓展。
BERT与GPT的其他一些细节区别:
- 数据上,GPT使用了BooksCorpus,而非ELMo所用的1B Word Benchmark数据集。虽然数据量相当,但后者打乱了句子顺序,破坏了语言的长距离结构信息,而前者数据为完整书籍。BERT中在BooksCorpus之外还使用了更庞大的Wikipedia数据。
- 结构上,GPT堆叠了12层Transformer模块、单向自注意力,并使用字节对编码BPE划分词片段。BERT则采用了24层Transformer模块、双向自注意力,并使用WordPiece划分词片段。
- 输入上,BERT在预训练阶段就进行句子拼接,且为了更明确区分拼接的两个句子,两个句子各加了一个额外的嵌入编码,最终模型输入为词嵌入(token embedding)、位置嵌入(position embedding)以及片段嵌入(segmentation embedding)三者之和。
- 微调上,GPT同时考虑了下游任务和语言模型,且经测试发现引入语言模型只有在数据量较大的任务中有正面效果。BERT中在微调时则未考虑语言模型。
- 结果上,BERT实现了对GPT的全面碾压,即便是网络尺寸相当的BERTBASE也实现了对GPT(及以往SOTA)的全面超越(除了双向自注意力,数据量更大也是一个原因)。
由于分别用语言模型和掩码语言训练,GPT与BERT的另一个重要区别是,GPT可直接用于(自回归)生成任务,而BERT则不能。不过最初的GPT工作并未实际考虑生成,轰动一时的独角兽短文是由GPT-2生成的。而考虑到BERT双向自注意力在语言理解上的巨大优势,不少工作尝试将BERT用于生成任务,最简单的做法是加回解码器,使用独立的单向自注意力模块用于生成,比如MASS, BART, T5都是这种做法。而前面提到的UniLM则尝试将单向、双向(掩码)语言模型(以及Seq2Seq)进行统一:通过调整自注意力掩码,将网络在多种任务上预训练,多任务共享模型,一起实现语言理解和生成。此外如果跳出自回归生成的限制,双向自注意力也可直接用于生成任务,比如KERMIT就提出通过半自回归生成基于双向自注意力模型实现语言生成,不过非自回归生成效果上暂时不如自回归生成,具体可参考NLP基本概念III对语言生成技术的介绍。
最后,在模型分析中,GPT检验了模型无任何微调(zero-shot)的表现,发现随着训练进行,模型在各类任务上的表现稳步提升;相对的,使用LSTM结构的模型zero-shot表现随训练提升的同时呈现更多的波动性,表明Transformer结构确实提升了模型通用能力。BERT则检验了模型尺寸的影响,不同于之前工作指出的模型太大效果并不一定理想,BERT发现大了就是好,由此开启预训练语言模型大型化的竞赛。两者还都测试了迁移层数的影响:GPT是结合微调分析,发现随层数增加最终模型效果增强;BERT则是参考ELMo,冻结模型,将各层隐状态整合为动态嵌入向量后,交由2层的双向LSTM处理下游任务,结果是直接拼接最后四层的隐状态效果最好,其它的如所有层加权求和或最后四层加权求和都稍差。
BERT的MLM任务和word2vec中CBOW训练任务很类似,所不同的是5年时间,GPU普及,算力及网络结构的提升,使得输入窗口(序列长度)可以扩展到整个语句甚至段落,而CBOW不考虑语序的缺点也由Transformer的位置编码巧妙解决。回头看作为起点的NNLM,是将语言模型最浅层的隐状态作为(静态)词嵌入,word2vec的思路则是既然是取最浅层作词嵌入,那就直接删掉中间的隐层,只保留嵌入层和输出层,实现了快速的静态嵌入。如果从深度网络的视角看,这显然是很不合理的,因为更深层网络能提取到更顶层和整体性的特征,但在当时算力受限情况下也没有更好的选择。而之后的动态嵌入(及语句嵌入)所做的其实都是将隐层重新加入模型,回归最初的NNLM,所不同的是不再关注浅层状态,而是取深层的隐状态作为(动态)词嵌入。但受限于RNN结构,NLP网络的深度很难加深,太深的网络不仅训练困难,效果也并不理想,始终徘徊在2-4层。直至Transformer的出现,GPT为12层Transformer模块(每个模块包含注意力和前馈网络2层),BERT则是24层Transformer模块,语言模型网络的深度迎来突破,同时也开启了预训练语言模型(Pretrained Language Models, PLM)的时代。Ruder将其称之为NLP的ImageNet时刻降临,斯坦福的相关研究者更是将以BERT, GPT3等为代表,基于Transformer和自监督学习的大规模预训练模型,视为继传统机器学习、深度学习之后的一个新范式——基础模型(Foundation models)。
PLM时代
在GPT和BERT之后,预训练语言模型(PLM)主要沿以下几个方向探索:
- 模型结构:各种自注意力机制的变种
- 模型尺度:更大或更小(压缩/加速)的模型
- 模型任务:各种花式的训练目标任务
其它的还包括通过知识图谱增强预训练模型,以及多语言、多模态的扩展等。关于注意力机制变种可参考NLP基本概念IV,模型压缩策略可参考模型压缩技术中的介绍,这些策略在语言模型中都有工作尝试,如基于剪枝的LayerDrop策略,知识蒸馏的TinyBERT、DistilBERT、MobileBERT,参数共享(及矩阵分解)的ALBERT,量化策略的Q-BERT、Q8BERT,动态调整的DynaBERT等,更详细的可参考这篇综述。下面主要讨论模型任务部分,参考了Devlin及李宏毅关于BERT变种的介绍。
BERT Family
语言模型就是终极的NLP任务
BERT超越GPT的核心原因就是双向注意力,而掩码语言模型是双向注意力得以应用的关键。而从BERT开始,各种适合双向注意力的训练任务被用于构建预训练模型。这些任务严格说并不算“语言模型”,不过这类自监督任务通常还是会归于预训练语言模型。
语音与影像上的神奇自督导式学习模型
https://www.bilibili.com/video/BV1nP4y1j7rZ?p=14
标准语言模型(LM)
语言模型最基础的任务就是基于输入序列的前面部分预测后续词语,即典型的自回归生成任务(Autoregressive Generation)。如果类比以BERT为代表的掩码语言模型,基本的语言模型其实也进行了掩码操作,不同的是语言模型为因果掩码,BERT所采用的是随机掩码,因此基础语言模型也被称为因果语言模型(Causal LM)。
语言模型任务没太多可变花样(GPT引用量与BERT差一个量级),主要是GPT系列在更大模型的道路上不断推进。GPT-2中将参数量和数据量增加了一个量级,并专注于GPT中曾提及的zero-shot表现,同时尝试了生成任务。而为了用有限的词表包含更多字符,GPT-2提出了直接针对二进制字节的BPE算法(byte-level BPE),可覆盖所有Unicode字符。GPT-3则在GPT-2之上将模型参数量增加两个量级,数据量增加一个量级,进一步探索超大模型完全不微调,在zero-shot, one-shot, few-shot下的表现。具体的,GPT会在输入中提供“整体任务描述 + 示例 + 具体问题提示”,由模型直接返回答案。注意这里的few-shot不同于通常理解的few-shot,没有任何训练/梯度更新过程,GPT-3称之为情境学习(in-context learning)。虽然GPT-3在很多任务中不如模型微调,但其所展现出的潜力,带火基于提示(Prompt)的模型调整技术,具体可参考下面Prompting部分介绍。比较奇怪的一点是GPT-3中随着模型增大,BatchSize增大,但学习率反而是下降的,跟通常认知似乎相悖。
掩码语言模型(MLM)
在BERT中输入是经过subword技术处理的token,掩码默认为token级别,即掩码的是词片段而非完整单词,MacBERT就提出掩码整个词(WWM),对于中文同样是掩码词而非单个字。ERNIE则提出掩码整个短语或实体名,SpanBERT又进一步推广至掩码长度可变的连续序列(长度由1到10,概率依次递减)。
BERT和GPT只取了Transformer的编码器或解码器,自然有人考虑用整个Transformer做预训练,这样做最基本的出发点是保留BERT双向注意力的同时,找回失去的语言生成能力。在MASS中这种迁移还是相对机械和受限的,编码器和解码器都会进行连续的掩码,并提供对应[MASK]标记。UniLM则是将编码器与解码器融合在一起,前面已有介绍。
Seq2Seq的优势到了BART才充分发挥出来:考虑到Seq2Seq输入和输出无需对应,BART中引入了各种不同的句子破坏方法。最直观的,此前的掩码操作中每个被掩码的token都需要提供对应的[MASK]标记,BART中则可直接完全删除单词(不提供[MASK]标记)。还有[MASK]标记填充(Text Infilling):将连续的多个掩码token空位用单个[MASK]标记填充,或者在原本没有掩码的位置,填充[MASK]作为干扰。如下图所示,对于编码器,AB之间并不存在缺失却被插入了空位,BE之间原本有两个缺失却只插入了一个空位,而对于解码器则按普通自回归生成操作,不进行额外掩码。除此之外,文章还尝试了打乱输入序列中句子顺序,以及序列的轮转(序列首尾相接,单词顺序不变,但改变起始位置)。最终结果上,空位填充的效果最好,而直接删除的效果也不错,单独的句子混排或序列轮换效果不好。

对下游任务微调时:对于分类任务,相同序列会依次输入编码器与解码器,并将解码器输出用于最终分类;对于文本生成任务,则类似普通Seq2Seq,解码器仅依靠编码器(不接收输入),通过自回归生成;对于翻译任务时,会在编码器前面额外加入新的编码器(预处理源语言),并对整个模型进行微调。
虽然BERT中选择只恢复掩码token,但整体上仍可视为去噪自编码(Vincent et al. 2008),即由引入随机噪声/破坏的输入重新原始数据,这点在BART中更为明显,目标为完整输入。而在此之前,Dai & Le (2015)中就将自编码(未加噪声)用于NLP任务的预训练,之后在Hill et al. (2016)则提出序列去噪自编码器SDAEs用于实现句嵌入。类似的策略在图片学习中同样有着更广泛应用,如填空、上色、拼图等任务。
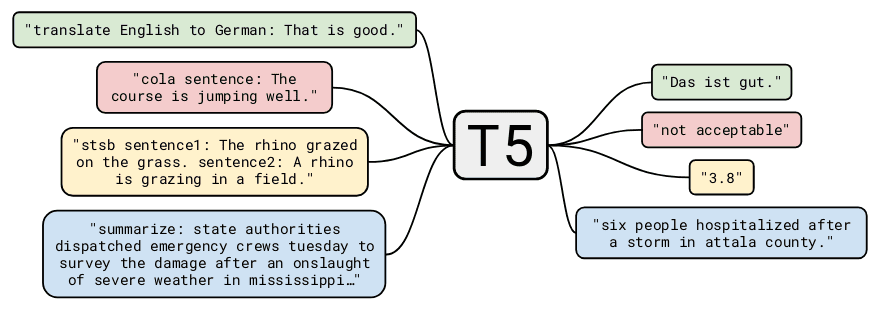
T5中则全面检验了各种模型超参数,探索最佳实践。T5采用所谓的"text-to-text"策略去统一各种任务,即所有任务都会以输入文本并返回文本的形式处理,而为区别不同任务,输入文本会加上用于标明任务的前缀信息(具体的前缀选择为超参数),具体如下图所示。这其实属于Prompting策略的一种,是任务适配模型,而非模型适配任务的思路。
在网络结构上,T5尝试了完整Transformer的Seq2Seq、单独解码器的语言模型LM,以及类似UniLM的编解码融合,文中称为前缀语言模型(PrefixLM)。结果Seq2Seq表现最好,编解码器共享参数也不错,超过了PrefixLM,而LM最差。
在训练任务上,类似于BART,T5尝试了各种输入破坏策略,包括混排、随机掩码、连续掩码、删除、空位填充等。发现除了随机混排效果差(破坏了结构信息),其他掩码策略互有胜负。需要注意基于计算量的考量,T5默认只解码掩码token,因此操作上和BART不同,比如删除单词时T5只会删除一段连续token,而空位填充时会对每个空位填充不同标记,在输出时用空位标记隔开每个空位对应的token。
在训练数据上,T5考虑了不同数据量、不同领域数据以及数据质量几个因素,最终发现更多的高质量数据效果最显著,领域相关数据确实有助于提升具体任务表现,但数据少了意味着模型容易过拟合,效果有时反而不好。
在训练策略上,T5测试了多任务训练、任务适配层以及渐进解冻方法,发现具体差别不是很大,直接的预训练+整体微调效果最好,多任务预训练表现一般,加上微调后表现可接近前者,渐进解冻相比整体微调效果稍差。
在模型规模上,T5实验了更大规模的模型、更多的训练步数、更大的batch尺寸以及多模型集成。最终发现还是增大模型规模最有效,规模受限时增加训练步数效果也不错,多模型集成同样可获得不错提升。
概括而言,经过对不同超参数的尝试,T5的主要结论为:
- 结构上,虽然编码器+解码器比单独解码器(或编码器)多了一倍参数量,但考虑到不需要拼接输入和输出,序列长度更短,计算量上两者相当。此外还可通过编码器和解码共享参数来降低参数量,模型效果并未有太多下降。
- 任务上,不同掩码策略对于模型最终表现影响不大,而考虑到计算量和(掩码之后)序列长度正相关,因此可从计算量的角度进行任务的选择。
- 整体上,增大模型规模及收集更多数据是获得提升的最佳策略。而如何有效的缩减模型尺寸,以及设计更高效利用训练数据的自监督任务仍需更多研究。
在之后研究中,还尝试了多语言预训练mT5以及各种Transformer模块变种对模型的影响,具体可论文作者的讲座。
排列语言模型(PLM)
XLNet提出了排列语言模型(Permutation Language Model, PLM):在MLM中是通过掩码挑选目标token,之后用所有输入去预测目标;PLM中则正好反过来,对任意目标token随机挑选自身之外的其它输入预测自身。具体的,PLM会对输入序列进行随机重排,对于序列中所有token只能取排列中位于其前面的token去预测自身。从自回归视角看这就是用之前序列预测当前位置输入,而如果从双向注意力视角看,考虑到随机排列,实际上就是随机挑选前后的一些token用于预测当前位置。需要注意的是PLM并没有破坏句子顺序,因为每个输入的位置嵌入始终是保持不变的,只是通过序列重排随机挑选用于预测的具体输入。或者可理解为序列本身没有重排,只是对编号做了随机重排来确定预测每个token的输入选择,实现上对应注意力矩阵的随机MASK。
PLM看似很完美,实现了双向注意力,还绕开了[MASK]标记,但其中存在一个问题:每次输入是随机的,模型并不清楚要预测哪个位置的输出,需提供位置信息。于是在预测位置的输入时需要用位置嵌入做query,而预测其他位置输入时,若选中了位置的输入又需要提供实际词嵌入作为content(key和value)。为此,作者提出了双流自注意力来实现这种操作,将上述query和content的嵌入拆开,每个输入都对应有独立的query和content嵌入:在计算query嵌入时,以位置嵌入或之前层输出的query嵌入作为query;计算content嵌入时,则跟正常注意力机制相同,以词嵌入或之前层输出的content嵌入作为query。如下图所示,更具体的可参考文章附录中的拆解图。
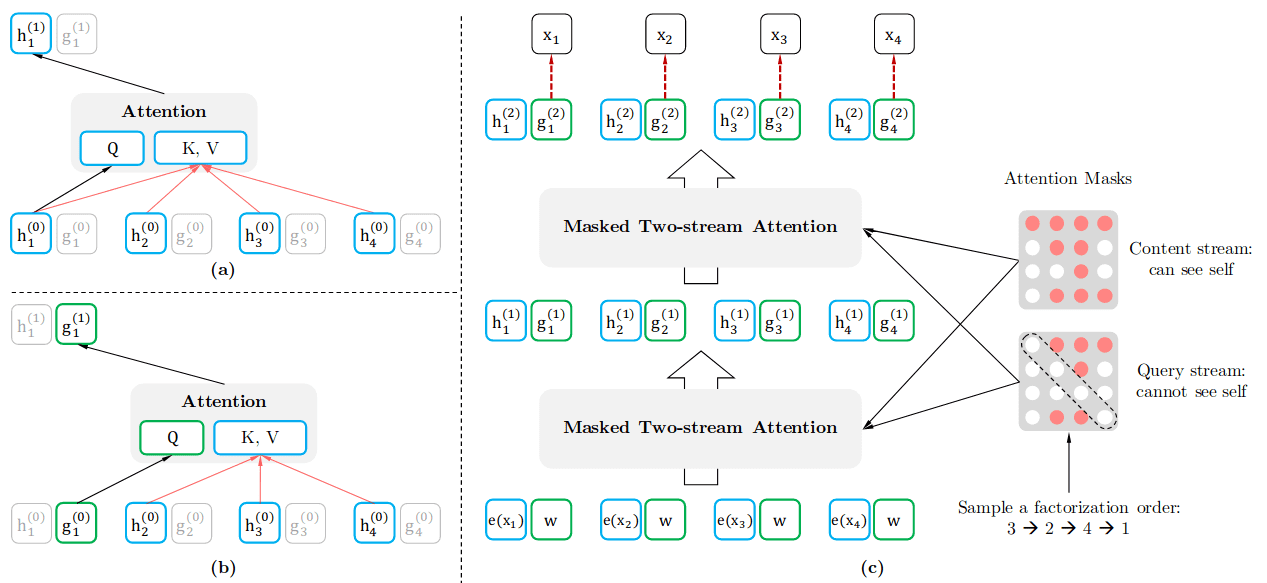
在实际训练中为便于优化,并不会预测排列中位于前面的token(用于预测的输入太少),而只会取位于后面的token作为预测目标,具体由超参数确定。未选中为预测目标的token并不需要计算query嵌入,且在预训练结束后,微调时会移除双流自注意力中的query流,只保留正常的content流用于下游任务。最后,XLNet是基于TransformerXL实现的,用到了后者的相对位置嵌入(relative position embedding)、序列循环记忆等策略。
输入替换检测(RTD)
前面的各种语言模型目标都是要预测/生成未看到的输入,考虑到从巨大的词表中选择正确单词,生成任务计算量通常是较大的。更为重要的,在掩码语言模型中只有15%的单词用作预训练任务目标,因此训练效率相对低。ELECTRA提出将生成任务替换为简单的判别任务:不去预测被MASK或替换的输入,而是判断输入是否有被替换,称之为输入替换检测(Replaced Token Detection, RTD)。具体的,输入会先经过掩码语言模型处理,将[MASK]部分填回,之后再由ELECTRA网络判断其中那些输入是被替换的,整体上如下图所示:
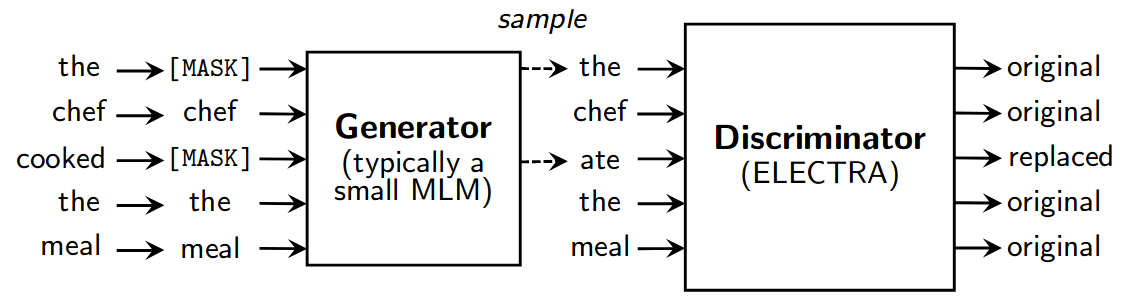
注意,虽然结构上非常类似GAN,但考虑到GAN训练困难,且目前在处理自然语言这类离散数据时效果不理想,模型没有选择生成对抗的训练方式,作为生成器的MLM是与判别器一起用最大似然损失进行训练:。事实上,文章中测试了对抗训练,但效果不如直接用最大似然,此外还尝试了分阶段训练,先单独训练生成器,再单独训练判别器,效果也不理想。注意,虽然是一起训练,但这里生成器与判别器实质上是独立的,训练时两者的梯度是各自独立反向传播,并不存在连通。对于生成器和判别器的大小,文章经过实验发现判别器大了更好,但生成器太大效果反而不好,通常取判别器的1/4到1/2时效果最好,这同时也降低了所需的计算量。
作为判别器的ELECTRA,输入中并不会出现[MASK]标记,也就不存在训练和实际不一致。而作为生成器的MLM也无需类似BERT对掩码做特殊处理,直接MASK而不用取一部分随机替换或不替换,且只需预测[MASK]对应输入。同时对判别器而言,每个输入单词都有可能被替换,因此都会执行判别任务,训练效果率上会更高。最后,预训练结束后,MLM生成器会直接移除,仅保留作为判别器的ELECTRA用于下游任务的微调和处理。
句子层次任务
MLM, PLM及RTD等都是token级别的任务,而为使模型更好提取句子层面的信息,BERT中提出了NSP((Next Sentence Prediction)任务,判断输入的两个句子是否为前后句,但在之后被发现其实作用不大。其原因可能是相邻句子语义相关联,因此任务对于BERT这类大模型而言太简单了。StructBERT提出可同时考虑上文、下文和随机文本三种情况,让模型判断具体是上文还是下文,又或者不相关。ALBERT中又提出了句子顺序预测SOP(Sentence Order Prediction)任务:将相邻的句子调换顺序,看模型能否分辨出来那些被调换了。相比从随机配对的句子中挑出关联句子,这些任务的难度有所增加,实验发现有助于提升预训练模型表现。
RoBERTa
最后专门讲下RoBERTa,全名A Robustly Optimized BERT Pretraining Approach,即如何更好的训练BERT,模型本身与BERT相同,主要改进在于超参数选择及训练细节:
- 核心结论为BERT仍显著欠拟合(significantly undertrained),因此RoBERTa使用了更多的数据、更大的batch size,训练更多epochs(总的step减少了)。其中更大的batch+数据并行(更多GPU),配合适当增大的学习率,可加快训练速度(You et al. 2019)。最终不仅明显超过了BERT,还超越了XLNet(数据和训练epoch更多)。
- 不过在Scaling Laws for Neural Language Models中OpenAI团队指出,使用更多的数据和训练步数让模型收敛的做法并非有限算力的最佳用法。对给定的算力预算限制,最佳选择是使用更大的模型,并在模型远未收敛就终止训练!模型的最佳参数量与可用算力呈指数关系,文章中的定量结果为(仅供参考)。
- 移除了NSP任务:RoBERTa经过实验发现,NSP任务并没有实质提升,简单将两个句子的拼接替换为更长的完整序列效果反而更好。
- 动态掩码:BERT中掩码是在数据预处理阶段进行的,数据复制10次后再随机掩码以减少重复,RoBERTa则是每个句子输入前动态掩码,最终效果上差别不大。
Fine-tuning
预训练模型用于下游任务传统的做法是作为通用特征提取器,稍复杂的可参照EMLo,整合不同层隐状态作为动态嵌入向量,输入针对具体任务的模型。而微调的做法则通常是沿用GPT所提出的策略,通过简单的输入变换和输出层(线性投影+Softmax)实现目标任务与预训练模型的匹配,之后在下游任务上微调整个模型。而且如前面介绍,Seq2Seq任务同样可通过编码器解码器拼接在一起的视角处理。
微调整个模型的主要问题在于,对于不同下游任务需要保存各自的模型,而随着预训练模型的巨大化,这种方式的成本也不断放大,此外在标签数据较少时大模型很容易过拟合。于是少参数迁移(Parameter-Efficient Transfer)成为关注重点,最简单的解决思路是冻结浅层网络,只调整深层(顶层)网络,而BitFit则提出了只微调偏置项(及输出层)的骚操作。还有一个解决思路是在预训练模型中引入统一的适配参数,针对下游任务微调时,固定预训练模型本身,只调整插入的适配参数(及输出层),微调后只需额外保存少量参数,也缓解了过拟合问题。Houlsby et al. (2019)就提出在Transformer模块内引入适配层(adapter),模型预训练后插入适配层,在微调阶段只改变适配层参数。Prefix-Tuning则提出在Transformer模块输入序列前插入特殊前缀(prefix),微调阶段只调整每层中这些前缀token的key和value向量(不需要输出,因此没有query)。
Prompting
Prompting是“任务适配模型而非模型适配任务”思想的延续:在GPT和BERT是通过输入变换和针对性的输出层实现预训练模型与不同下游任务间的适配,Prompting技术则更进一步,参照自然语言设计合适的Prompt对输入进行变换,为模型提供目标任务的“提示”,使模型可直接返回预期结果而无需任何针对性的输出层。这种策略可追溯到将多项自然语言任务统一为问答形式的DMN(Kumar et al. 2016)和decaNLP(McCann et al. 2018),之后在GPT2和T5中得到进一步发展,并最终由GPT3带火。
Prompt的出发点是将任务变得类似模型在预训练阶段就会遇到的自然语言问题,从而可更直接利用预训练成果。Fine-tuning中还需要加针对任务的输出层,Prompting中预训练模型则完全保持原样。看起来简单不少,但实际中不同Prompt,模型表现会有所不同,类似于使用搜索引擎时提供不同关键词。比如Zhao et al. (2021)就指出在zero-shot下模型表现对Prompt选择敏感;不过Le Scao & Rush (2021)又指出Prompt+微调对Prompt不敏感,并且能改善模型Few-shot表现,所以Prompt具体影响还有进一步待探讨。
为找到合适的Prompt,一个角度是将Prompt作为模型超参数进行设计,整体上可分为两类:一种是以前缀(prefix)的形式标明问题(T5/GPT3),一种是以填空(cloze)的方式指示问题(LAMA)。粗略来说,前者更适合标准语言模型LM或PrefixLM,后者则更适用于掩码语言模型。具体实现上可以是手动设计,也可以是基于外部模型通过聚类/变换/生成等方式自动搜索(LPAQA、LM-BFF)。另一个思路是直接将Prompt作为模型参数(而非超参数),让模型自行学习最佳Prompt,具体又可分两类:一类是从离散词表中选择合适词语,另一类是直接学习Prompt的连续嵌入。前者可解释性稍强(AdvTrigger、AutoPrompt),后者则更为灵活(P-tuning、SoftPrompt),类似简化版的Prefix-Tuning。最后,Prompt可进一步扩展至多个,比如同一个问题换用几种方式提问(ensemble),又或者提供几个回答样例(GPT3的情景学习),以及对Prompt进行合成或分解操作。
除了在输入中增加提示信息(Prompt),某些情况下输出标签也需要进行变换以适配模型。比如预期标签为"excellent, good, OK, bad, horrible",而zero-shot的预训练模型针输出的可能是"cool, fine, great, terrific, amazing, awful, terrible"。在Fine-tuning中可通过定制的输出层强迫模型输出指定标签,但在Prompting中并不存在这样的输出层,需要反过来让任务目标尽量靠近模型。也就是要发掘预训练阶段模型所见到的自然语言常见表达,建立标签与自然语言间更合理的映射,以最大程度发挥预训练模型潜力。这种标签映射通常被称为Verbalizer(标签词语化转换器),具体实现上同样有手动设计(PET/iPET及其改进)和自动搜索(PETAL、LM-BFF)等不同做法。还有研究(NullPrompt)提出Verbalizer结合适当微调可替代对Prompt的设计。
在学习策略上,理想情况当然是类似于GPT3,冻结整个预训练模型,完全无需任何训练的zero-shot或few-short(priming)。但这严重依赖昂贵的大模型,同时也未能发挥模型的全部潜力。受限于算力,能训练GPT3规模模型的人暂时是少数,更现实的做法是结合Prompt对模型进行微调(Prompt-Based Fine-tuning),具体实现上跟直接微调类似,有不同选择:
- 基于预先设计的Prompt,调整预训练模型参数 T5, PET/iPET, LM-BFF
- 将Prompt作为模型参数,冻结模型仅调整Prompt SoftPrompt, AutoPrompt
- 将Prompt作为模型参数,与模型一起进行调整 P-tuning
除了上述策略外,还有Prompt+多任务微调(Wei et al. 2021, Sanh et al. 2021)以及在预训练阶段就引入Prompt信息,即所谓的Prompt-aware Pre-training(AdaPrompt)等操作,总之作为新兴领域各种策略都有人尝试,更多可参考这篇综述。相比直接微调,基于Prompt微调在标签数据稀缺时效果更好。Le Scao & Rush (2021)对比了两种方法在不同任务下的表现,发现在大部分任务上基于Prompt的微调在Few-shot情况下具有明显优势(WiC任务中产生了负面效果),而随着数据量增加这种差距随之缩小。部分原因可能是在Prompt的提供了部分任务相关的知识,更充分发挥了预训练模型的能力,尤其是经过搜索设计得到的Prompt。
扩展阅读:
Word Embedding - Wikipedia
Neural Net Language Models
NLP Course | For You - Elena Voita
A Review of the Neural History of NLP
Learning Word Embedding
Compact word vectors with Bloom embeddings
Generalized Language Models
Pre-trained Models for NLP: A Survey
Transfer Learning in NLP
How Big Should My Language Model Be?
How many data points is a prompt worth?