广义平稳随机过程、各态历经性;匹配滤波;高斯过程、随机游走、泊松过程、马尔科夫链
随机过程基础
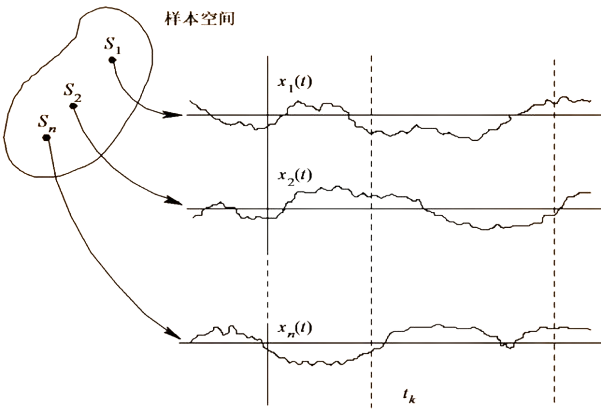
随机过程就是每刻取值都随机的过程。如上图所示:从纵向角度,对于固定的时间t k t_k t k x ( t k ) \mathbf{x}(t_k) x ( t k ) x ( t ) x(t) x ( t ) x ( t ) \mathbf{x}(t) x ( t )
随机过程在某种程度上可理解为以“函数”为样本的随机变量,每次“试验”得到的不是一个数值,而是一系列随机数值所组成的函数(实现)。其随机性源自x \mathbf{x} x t t t x ( t ) x(t) x ( t )
相关的一些符号介绍:
x ( t ) , y ( t ) \mathbf{x}(t), \mathbf{y}(t) x ( t ) , y ( t ) t t t x ( t 1 ) , x ( t 2 ) \mathbf{x}(t_1), \mathbf{x}(t_2) x ( t 1 ) , x ( t 2 ) x ( t ) , y ( t ) x(t), y(t) x ( t ) , y ( t ) x 1 ( t ) , x 2 ( t ) x_1(t), x_2(t) x 1 ( t ) , x 2 ( t ) { x i ( t ) } \{x_i(t)\} { x i ( t ) } x ( t 1 ) , x ( t 2 ) x(t_1), x(t_2) x ( t 1 ) , x ( t 2 ) x 1 ( t 1 ) , x 2 ( t 2 ) x_1(t_1), x_2(t_2) x 1 ( t 1 ) , x 2 ( t 2 )
从随机变量角度,最基本的是从统计上进行研究,获取确定性的统计量,为此需先引入描述随机过程的概率分布。任意时刻t t t F ( x ; t ) = P { x ( t ) ≤ x } F(x; t) = P\{\mathbf{x}(t) \le x\} F ( x ; t ) = P { x ( t ) ≤ x } f ( x ; t ) = ∂ F ( x ; t ) ∂ x f(x;t) = \frac{\partial F(x; t)}{\partial x} f ( x ; t ) = ∂ x ∂ F ( x ; t ) x ( t ) x(t) x ( t ) n n n n n n { x i ( t ) } \{x_i(t)\} { x i ( t ) } t t t x x x F ( x ; t ) F(x; t) F ( x ; t )
μ ( t ) = E { x ( t ) } = ∫ x ( t ) f ( x ; t ) d x \mu(t) = E\{ \mathbf{x}(t) \} = \int x(t) f(x; t) dx
μ ( t ) = E { x ( t ) } = ∫ x ( t ) f ( x ; t ) d x
σ 2 ( t ) = E { [ x ( t ) − μ ( t ) ] 2 } = ∫ [ x ( t ) − μ ( t ) ] 2 f ( x ; t ) d x \sigma^2(t) = E\left\{ \big[\mathbf{x}(t)-\mu(t)\big]^2 \right\} = \int \big[x(t)-\mu(t)\big]^2 f(x; t) dx
σ 2 ( t ) = E { [ x ( t ) − μ ( t ) ] 2 } = ∫ [ x ( t ) − μ ( t ) ] 2 f ( x ; t ) d x
显然,一般情况下均值和方差会随时间变化。注意随机过程是关于时间的随机变量,而其均值和方差则是关于时间的确定性函数。
进一步的,对于随机过程中不同时刻的随机变量x ( t 1 ) , x ( t 2 ) \mathbf{x}(t_1), \mathbf{x}(t_2) x ( t 1 ) , x ( t 2 ) F ( x 1 , x 2 ; t 1 , t 2 ) = P { x ( t 1 ) ≤ x 1 , x ( t 2 ) ≤ x 2 } F(x_1, x_2; t_1, t_2) = P\{\mathbf{x}(t_1) \le x_1, \mathbf{x}(t_2) \le x_2\} F ( x 1 , x 2 ; t 1 , t 2 ) = P { x ( t 1 ) ≤ x 1 , x ( t 2 ) ≤ x 2 } f ( x 1 , x 2 ; t 1 , t 2 ) = ∂ 2 F ( x 1 , x 2 ; t 1 , t 2 ) ∂ x 1 ∂ x 2 f(x_1, x_2; t_1, t_2) = \frac{\partial^2 F(x_1, x_2; t_1, t_2)}{\partial x_1 \partial x_2} f ( x 1 , x 2 ; t 1 , t 2 ) = ∂ x 1 ∂ x 2 ∂ 2 F ( x 1 , x 2 ; t 1 , t 2 ) 自相关 函数:
r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 2 ) } = ∬ x 1 ( t 1 ) x 2 ( t 2 ) f ( x 1 , x 2 ; t 1 , t 2 ) d x 1 d x 2 r_{\mathbf{xx}}(t_1, t_2) = E\big\{ \mathbf{x}(t_1)\mathbf{x}(t_2) \big\} = \iint x_1(t_1) x_2(t_2) f(x_1, x_2; t_1, t_2) dx_1 dx_2
r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 2 ) } = ∬ x 1 ( t 1 ) x 2 ( t 2 ) f ( x 1 , x 2 ; t 1 , t 2 ) d x 1 d x 2
类似的,还可以定义两个随机过程x ( t ) , y ( t ) \mathbf{x}(t), \mathbf{y}(t) x ( t ) , y ( t ) 互相关 函数:
r x y ( t 1 , t 2 ) = E { x ( t 1 ) y ( t 2 ) } = ∬ x ( t 1 ) y ( t 2 ) f ( x , y ; t 1 , t 2 ) d x d y r_{\mathbf{xy}}(t_1, t_2) = E\big\{ \mathbf{x}(t_1)\mathbf{y}(t_2) \big\} = \iint x(t_1) y(t_2) f(x, y; t_1, t_2) dx dy
r x y ( t 1 , t 2 ) = E { x ( t 1 ) y ( t 2 ) } = ∬ x ( t 1 ) y ( t 2 ) f ( x , y ; t 1 , t 2 ) d x d y
在计算自相关/互相关前减去均值,可以得到对应的自协方差(autocovariance)γ x x ( t 1 , t 2 ) \gamma_{\mathbf{xx}}(t_1, t_2) γ x x ( t 1 , t 2 ) γ x y ( t 1 , t 2 ) \gamma_{\mathbf{xy}}(t_1, t_2) γ x y ( t 1 , t 2 )
γ x x ( t 1 , t 2 ) = E { [ x ( t 1 ) − μ ( t 1 ) ] [ x ( t 2 ) − μ ( t 2 ) ] } = r x x ( t 1 , t 2 ) − μ ( t 1 ) μ ( t 2 ) \gamma_{\mathbf{xx}}(t_1, t_2) = E\big\{ [\mathbf{x}(t_1) -\mu(t_1)][\mathbf{x}(t_2)-\mu(t_2)] \big\} = r_{\mathbf{xx}}(t_1, t_2) - \mu(t_1)\mu(t_2)
γ x x ( t 1 , t 2 ) = E { [ x ( t 1 ) − μ ( t 1 ) ] [ x ( t 2 ) − μ ( t 2 ) ] } = r x x ( t 1 , t 2 ) − μ ( t 1 ) μ ( t 2 )
γ x y ( t 1 , t 2 ) = E { [ x ( t 1 ) − μ x ( t 1 ) ] [ y ( t 2 ) − μ y ( t 2 ) ] } = r x y ( t 1 , t 2 ) − μ x ( t 1 ) μ y ( t 2 ) \gamma_{\mathbf{xy}}(t_1, t_2) = E\big\{ [\mathbf{x}(t_1) -\mu_\mathbf{x}(t_1)][\mathbf{y}(t_2)-\mu_\mathbf{y}(t_2)] \big\} = r_{\mathbf{xy}}(t_1, t_2) - \mu_\mathbf{x}(t_1)\mu_\mathbf{y}(t_2)
γ x y ( t 1 , t 2 ) = E { [ x ( t 1 ) − μ x ( t 1 ) ] [ y ( t 2 ) − μ y ( t 2 ) ] } = r x y ( t 1 , t 2 ) − μ x ( t 1 ) μ y ( t 2 )
类似随机变量方差与协方差的关系var { x } = cov { x , x } \text{var}\{\mathbf{x}\} = \text{cov}\{\mathbf{x}, \mathbf{x}\} var { x } = cov { x , x } σ 2 ( t ) = γ x x ( t , t ) = r x x ( t , t ) − μ 2 ( t ) \sigma^2(t) = \gamma_{\mathbf{xx}}(t, t) = r_{\mathbf{xx}}(t, t) - \mu^2(t) σ 2 ( t ) = γ x x ( t , t ) = r x x ( t , t ) − μ 2 ( t )
更进一步有n n n F ( x 1 , . . . , x n ; t 1 , . . . , t n ) = P { x ( t 1 ) ≤ x 1 , . . . , x ( t n ) ≤ x n } F(x_1, ..., x_n; t_1, ..., t_n) = P\{\mathbf{x}(t_1) \le x_1, ..., \mathbf{x}(t_n) \le x_n\} F ( x 1 , . . . , x n ; t 1 , . . . , t n ) = P { x ( t 1 ) ≤ x 1 , . . . , x ( t n ) ≤ x n } f ( x 1 , . . . , x n ; t 1 , . . . , t n ) f(x_1, ..., x_n; t_1, ..., t_n) f ( x 1 , . . . , x n ; t 1 , . . . , t n ) n n n n n n
最后,上面的讨论都仅限于对应实值函数的随机过程,对复值过程可通过两个实随机过程进行描述z ( t ) = x ( t ) + i y ( t ) \mathbf{z}(t) = \mathbf{x}(t) + i \mathbf{y}(t) z ( t ) = x ( t ) + i y ( t ) r z z ( t 1 , t 2 ) = E { z ( t 1 ) z ( t 2 ) ‾ } r_\mathbf{zz}(t_1, t_2)= E\big\{ \mathbf{z}(t_1)\overline{\mathbf{z}(t_2)} \big\} r z z ( t 1 , t 2 ) = E { z ( t 1 ) z ( t 2 ) }
广义平稳过程
(狭义)平稳过程:x ( t ) \mathbf{x}(t) x ( t ) x ( t + ϵ ) \mathbf{x}(t+\epsilon) x ( t + ϵ ) n n n n n n n n n n n n r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 1 ) } = E { x ( t 1 + ϵ ) x ( t 1 + ϵ ) } ≡ r x x ( t 1 − t 2 ) r_{\mathbf{xx}}(t_1, t_2) = E\{\mathbf{x}(t_1)\mathbf{x}(t_1)\}= E\{\mathbf{x}(t_1+\epsilon)\mathbf{x}(t_1+\epsilon)\} \equiv r_\mathbf{xx}(t_1-t_2) r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 1 ) } = E { x ( t 1 + ϵ ) x ( t 1 + ϵ ) } ≡ r x x ( t 1 − t 2 )
广义平稳过程:均值为常数,且自相关函数只依赖时间差 x ( t ) = cos ( t + θ ) \mathbf{x}(t) = \cos(t+\bm{\theta}) x ( t ) = cos ( t + θ ) θ \bm{\theta} θ { 0 , 1 2 π , π , 3 2 π } \{0, \frac{1}{2}\pi, \pi, \frac{3}{2}\pi\} { 0 , 2 1 π , π , 2 3 π }
联合平稳性:对两个随机过程x ( t ) , y ( t ) \mathbf{x}(t), \mathbf{y}(t) x ( t ) , y ( t ) 互相关 函数只依赖时间差。
其他平稳形式:周期平稳、渐近平稳、增量平稳、局部平稳
在时域中,广义平稳过程均值恒定,自相关函数只依赖时间差,并不直观。后面会介绍随机过程自相关函数与功率谱可构成傅里叶变换对,自相关只依赖时间差,即对应确定的功率谱。因此在频域视角下,广义平稳随机过程是频率成分固定、相位随机的过程,而非平稳过程则是频率成分随时间演化的过程 。
广义平稳过程自相关性质:
只是时间差值的函数,记为r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ )
对实随机过程x ( t ) \mathbf{x}(t) x ( t ) r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ )
偶对称 r x x ( τ ) = r x x ( − τ ) r_\mathbf{xx}(\tau) = r_\mathbf{xx}(-\tau) r x x ( τ ) = r x x ( − τ )
零点值最大 r x x ( 0 ) ≥ ∣ r x x ( τ ) ∣ r_\mathbf{xx}(0) \ge |r_\mathbf{xx}(\tau)| r x x ( 0 ) ≥ ∣ r x x ( τ ) ∣
零点值 r x x ( 0 ) = r x x ( t , t ) = E { x 2 ( t ) } = σ 2 + μ 2 r_\mathbf{xx}(0) = r_\mathbf{xx}(t, t) = E\{\mathbf{x}^2(t)\} = \sigma^2 + \mu^2 r x x ( 0 ) = r x x ( t , t ) = E { x 2 ( t ) } = σ 2 + μ 2 μ 2 \mu^2 μ 2 σ 2 \sigma^2 σ 2 r x x ( 0 ) r_\mathbf{xx}(0) r x x ( 0 )
r x x ( τ ) = γ x x ( τ ) + μ 2 r_\mathbf{xx}(\tau) = \gamma_\mathbf{xx}(\tau) + \mu^2 r x x ( τ ) = γ x x ( τ ) + μ 2 周期性 如果r x x ( T ) = r x x ( 0 ) r_\mathbf{xx}(T) = r_\mathbf{xx}(0) r x x ( T ) = r x x ( 0 ) r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ ) x ( t ) \mathbf{x}(t) x ( t ) T T T r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ ) x ( t ) \mathbf{x}(t) x ( t ) r x x ( 0 ) > ∣ r x x ( τ ) ∣ r_\mathbf{xx}(0) > |r_\mathbf{xx}(\tau)| r x x ( 0 ) > ∣ r x x ( τ ) ∣
对于广义联合平稳过程的互相关r x y ( τ ) r_\mathbf{xy}(\tau) r x y ( τ ) r x y ( τ ) = r y x ( − τ ) r_\mathbf{xy}(\tau) = r_\mathbf{yx}(-\tau) r x y ( τ ) = r y x ( − τ ) r x y ( τ ) ≤ 1 2 [ r x x ( 0 ) + r x x ( 0 ) ] ≤ r x x ( 0 ) r y y ( 0 ) r_\mathbf{xy}(\tau) \le \frac{1}{2}[r_\mathbf{xx}(0) + r_\mathbf{xx}(0)] \le \sqrt{r_\mathbf{xx}(0) r_\mathbf{yy}(0)} r x y ( τ ) ≤ 2 1 [ r x x ( 0 ) + r x x ( 0 ) ] ≤ r x x ( 0 ) r y y ( 0 )
相关函数与相关系数 ρ ( X , Y ) = c o v ( X , Y ) σ X σ Y \rho(\mathrm{X},\mathrm{Y}) = \frac{\mathrm{cov}(X, Y)}{\sigma_X \sigma_Y} ρ ( X , Y ) = σ X σ Y c o v ( X , Y ) [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ]
ρ x , y ( τ ) = γ x , y ( τ ) σ x σ x = r x , y ( τ ) − μ x μ y σ x σ y \rho_{\mathbf{x},\mathbf{y}}(\tau) = \frac{\gamma_{\mathbf{x},\mathbf{y}}(\tau)}{\sigma_\mathbf{x} \sigma_\mathbf{x}} = \frac{r_{\mathbf{x},\mathbf{y}}(\tau) - \mu_\mathbf{x} \mu_\mathbf{y}}{\sigma_\mathbf{x} \sigma_\mathbf{y}}
ρ x , y ( τ ) = σ x σ x γ x , y ( τ ) = σ x σ y r x , y ( τ ) − μ x μ y
随机向量与协方差矩阵 r x y ( t 1 , t 2 ) = E { x ( t 1 ) y ( t 2 ) } r_\mathbf{xy}(t_1, t_2) = E\{ \mathbf{x}(t_1)\mathbf{y}(t_2) \} r x y ( t 1 , t 2 ) = E { x ( t 1 ) y ( t 2 ) } R X Y = E { X Y T } R_\mathbf{XY} = E\{ \mathbf{XY}^T \} R X Y = E { X Y T } ( R X Y ) i j = E { X i Y j } (R_\mathbf{XY})_{ij} = E\{ X_i Y_j \} ( R X Y ) i j = E { X i Y j } K X Y = E { ( X − E { X } ) ( Y − E { Y } ) T } K_\mathbf{XY} = E\Bigl\{ \bigl(\mathbf{X}-E\{\mathbf{X}\}\bigr)\bigl(\mathbf{Y}-E\{\mathbf{Y}\}\bigr)^T \Bigr\} K X Y = E { ( X − E { X } ) ( Y − E { Y } ) T }
而通常说的,协方差矩阵 一般是自协方差矩阵:
Σ = K X X = E { ( X − E { X } ) ( X − E { X } ) T } \Sigma = K_\mathbf{XX} = E\Bigl\{ \bigl(\mathbf{X}-E\{\mathbf{X}\}\bigr)\bigl(\mathbf{X}-E\{\mathbf{X}\}\bigr)^T \Bigr\}
Σ = K X X = E { ( X − E { X } ) ( X − E { X } ) T }
从随机向量整体角度理解,协方差矩阵是随机向量的方差v a r { X } \mathrm{var}\{\mathbf{X}\} v a r { X }
进一步的,还可引入相关系数矩阵,即归一化的自相关矩阵,也可理解为归一化随机向量X − μ X σ X = ( X i − μ X i σ X i ) \frac{\mathbf{X}-\bm{\mu}_\mathbf{X}}{\bm{\sigma}_\mathbf{X}} = \left(\frac{X_i-\mu_{X_i}}{\sigma_{X_i}}\right) σ X X − μ X = ( σ X i X i − μ X i ) [ − 1 , 1 ] [-1, 1] [ − 1 , 1 ]
自相关矩阵 R X X = E { X X T } R_\mathbf{XX} = E\{ \mathbf{XX}^T \} R X X = E { X X T }
协方差矩阵 Σ = R X X − E { X } E { X } T \Sigma = R_\mathbf{XX} - E\{\mathbf{X}\}E\{\mathbf{X}\}^T Σ = R X X − E { X } E { X } T
相关(系数)矩阵 C X X = ( Σ i j σ X i σ X j ) C_\mathbf{XX} = \left(\frac{\Sigma_{ij}}{\sigma_{X_i}\sigma_{X_j}}\right) C X X = ( σ X i σ X j Σ i j )
自相关矩阵和协方差矩阵都是对称矩阵,同时也都是半正定矩阵(特征值非负)。在Numpy中,一维序列相关为np.correlate,随机向量协方差为np.cov(输入的行对应单个随机变量,列对应单次观测),而对应的相关系数为np.corrcoef。
各态历经性
前面都是从统计角度分析随机过程,作为无数具体实现(样本函数)组成的系综,实际中通常仅能获得随机过程的少数有限次、甚至单次的实现(如股价曲线),从统计角度的分析并不现实。最好的情况是基于单次实现就可获取对系统整体统计性质的认知,这种优良特性被称为各态历经性/遍历性(Ergodicity)。这一概念源自统计物理,在随机过程中可简单描述为:系综期望(统计平均)等于具体实现的时间平均(ensemble average == time average)。基于各态历经性,对随机过程的描述可由(状态)空间变换到时间,获取单次试验数据即可展开分析,而无需进行大量重复试验。
μ ( t ) = E [ x ( t ) ] = ∫ x ( t ) f ( x ; t ) d x ↔ μ x = ⟨ x ( t ) ⟩ = lim T → ∞ 1 2 T ∫ − T T x ( t ) d t \mu(t) = E[\mathbf{x}(t)] = \int x(t) f(x;t) dx ~~~ \leftrightarrow ~~~ \mu_x = ⟨x(t)⟩ = \lim_{T\rightarrow \infty} \frac{1}{2T}\int_{-T}^{T} x(t) dt
μ ( t ) = E [ x ( t ) ] = ∫ x ( t ) f ( x ; t ) d x ↔ μ x = ⟨ x ( t ) ⟩ = T → ∞ lim 2 T 1 ∫ − T T x ( t ) d t
r x x ( t , t + τ ) = E [ x ( t ) x ( t + τ ) ] ↔ r x x ( τ ) = lim T → ∞ 1 2 T ∫ − T T x ( t ) x ( t + τ ) d t r_\mathbf{xx}(t, t+\tau) = E[\mathbf{x}(t)\mathbf{x}(t+\tau)] ~~~ \leftrightarrow ~~~ r_{xx}(\tau) = \lim_{T\rightarrow \infty} \frac{1}{2T}\int_{-T}^{T} x(t)x(t+\tau) dt
r x x ( t , t + τ ) = E [ x ( t ) x ( t + τ ) ] ↔ r x x ( τ ) = T → ∞ lim 2 T 1 ∫ − T T x ( t ) x ( t + τ ) d t
注意,各态历经性是与具体统计量直接相关联的,如均值各态历经、自相关/自协方差各态历经等。实际中各态历经通常默认指自相关各态历经(也自然暗含均值各态历经)。由于随机过程具体实现的时间平均⟨ x ( t ) ⟩ ⟨x(t)⟩ ⟨ x ( t ) ⟩ μ ( t ) = E [ x ( t ) ] \mu(t) = E[\mathbf{x}(t)] μ ( t ) = E [ x ( t ) ] r x x ( τ ) r_{xx}(\tau) r x x ( τ ) r x x ( t , t + τ ) r_\mathbf{xx}(t, t+\tau) r x x ( t , t + τ )
“各态历经”字面理解就是要每次实现都会遍历所有可能的状态。为直观的理解各态历经性,可将对随机变量的采样视为随机过程:逐次独立采样所构成的时间序列可理解为该随机过程的一次实现,而同时的无数次独立采样则对应随机过程系综的时间切片,显然前后两者具有相同的统计性质,即单次试验的时间平均等于系综平均。最简单的,一个色子的连续投掷与无数色子的同时投掷在统计上是没有区别的。
相对的,如果先后采样不独立,则采样过程就可能不再具有各态历经性,比如初始时刻取值是随机变量,但其后所有时刻取值都等于初始时刻值。这种情况下,每次实现显然无法遍历所有状态:随机过程具体实现的时间平均就等于初始时刻取值,是随机变量,而系统的系综平均则为初始时刻随机变量的均值,为固定值,因此不是各态历经的。事实上,该过程是平稳的,但非各态历经,类似的过程还有随机游走。
一般的,随机过程的时间平均应为随机变量(或过程),对于均值和自相关/自协方差有:
μ x = ⟨ x ( t ) ⟩ = lim T → ∞ 1 T ∫ − T / 2 T / 2 x ( t ) d t r x ( τ ) = ⟨ x ( t ) x ( t + τ ) ⟩ = lim T → ∞ 1 T ∫ − T / 2 T / 2 x ( t ) x ( t + τ ) d t γ x ( τ ) = ⟨ [ x ( t ) − μ x ] [ x ( t + τ ) − μ x ] ⟩ = r x ( τ ) − μ x 2 \begin{aligned}
\bm{\mu}_\mathbf{x} &= ⟨\mathbf{x}(t)⟩ = \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} \mathbf{x}(t) dt\\
\bm{r}_\mathbf{x}(\tau) &= \big⟨\mathbf{x}(t)\mathbf{x}(t+\tau)\big⟩ = \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} \mathbf{x}(t)\mathbf{x}(t+\tau) dt\\
\bm{\gamma}_\mathbf{x}(\tau) &= \big⟨[\mathbf{x}(t)-\bm{\mu}_\mathbf{x}][\mathbf{x}(t+\tau)-\bm{\mu}_\mathbf{x}]\big⟩ = \bm{r}_\mathbf{x}(\tau) - \bm{\mu}_\mathbf{x}^2
\end{aligned} μ x r x ( τ ) γ x ( τ ) = ⟨ x ( t ) ⟩ = T → ∞ lim T 1 ∫ − T / 2 T / 2 x ( t ) d t = ⟨ x ( t ) x ( t + τ ) ⟩ = T → ∞ lim T 1 ∫ − T / 2 T / 2 x ( t ) x ( t + τ ) d t = ⟨ [ x ( t ) − μ x ] [ x ( t + τ ) − μ x ] ⟩ = r x ( τ ) − μ x 2
而各态历经则要求该随机变量为常数(或确定函数),即:
μ x = E { x ( t ) } = μ x , r x ( τ ) = r x x ( τ ) = r x x ( τ ) , γ x ( τ ) = γ x x ( τ ) = γ x x ( τ ) \begin{aligned}
\bm{\mu}_\mathbf{x} &= E\{\mathbf{x}(t)\} = \mu_x,\\
\bm{r}_\mathbf{x}(\tau) &= r_\mathbf{xx}(\tau) = r_{xx}(\tau),\\
\bm{\gamma}_\mathbf{x}(\tau) &= \gamma_\mathbf{xx}(\tau) = \gamma_{xx}(\tau)
\end{aligned} μ x r x ( τ ) γ x ( τ ) = E { x ( t ) } = μ x , = r x x ( τ ) = r x x ( τ ) , = γ x x ( τ ) = γ x x ( τ )
以均值各态历经为例,在统计上,这对应于:
E { x ( t ) } = μ x = μ x , Var { μ x } = E { [ μ x − μ x ] 2 } = E { μ x 2 } − μ x 2 = 0 E\{\mathbf{x}(t)\} = \bm{\mu}_\mathbf{x} = \mu_x, ~~~~ \text{Var}\{\bm{\mu}_\mathbf{x}\} = E\{[\bm{\mu}_\mathbf{x}- \mu_x]^2\} = E\{\bm{\mu}_\mathbf{x}^2\} - \mu_x^2 = 0
E { x ( t ) } = μ x = μ x , Var { μ x } = E { [ μ x − μ x ] 2 } = E { μ x 2 } − μ x 2 = 0
利用期望、极限及积分的可交换性(这里不讨论严格的数学要求):
E { μ x } = lim T → ∞ 1 T ∫ − T / 2 T / 2 E { x ( t ) } d t , E { μ x 2 } = lim T → ∞ 1 T 2 ∫ − T / 2 T / 2 ∫ − T / 2 T / 2 E { x ( t 1 ) x ( t 2 ) } d t 1 d t 2 \begin{aligned}
E\{\bm{\mu}_\mathbf{x}\} &= \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} E\{\mathbf{x}(t)\} dt,\\
E\{\bm{\mu}_\mathbf{x}^2\} &= \lim_{T\rightarrow \infty} \frac{1}{T^2}\int_{-T/2}^{T/2}\int_{-T/2}^{T/2} E\{\mathbf{x}(t_1)\mathbf{x}(t_2)\} dt_1dt_2
\end{aligned} E { μ x } E { μ x 2 } = T → ∞ lim T 1 ∫ − T / 2 T / 2 E { x ( t ) } d t , = T → ∞ lim T 2 1 ∫ − T / 2 T / 2 ∫ − T / 2 T / 2 E { x ( t 1 ) x ( t 2 ) } d t 1 d t 2
即,为检验均值各态历经,不仅要考虑随机过程的均值μ ( t ) = E { x ( t ) } \mu(t) = E\{\mathbf{x}(t)\} μ ( t ) = E { x ( t ) } r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 2 ) } r_\mathbf{xx}(t_1, t_2) = E\{\mathbf{x}(t_1)\mathbf{x}(t_2)\} r x x ( t 1 , t 2 ) = E { x ( t 1 ) x ( t 2 ) } E { μ x } = E { x ( t ) } = μ x E\{\bm{\mu}_\mathbf{x}\} = E\{\mathbf{x}(t)\} = \mu_x E { μ x } = E { x ( t ) } = μ x Var { μ x } \text{Var}\{\bm{\mu}_\mathbf{x}\} Var { μ x } 充要 条件是:
lim T → ∞ 1 T ∫ − T / 2 T / 2 γ x x ( τ ) d τ = 0 或 lim T → ∞ 1 T ∫ − T / 2 T / 2 r x x ( τ ) d τ = μ x 2 \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} \gamma_\mathbf{xx}(\tau) d\tau = 0 ~~~~~ \text{\small 或} ~~~~~ \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} r_\mathbf{xx}(\tau) d\tau = \mu_x^2
T → ∞ lim T 1 ∫ − T / 2 T / 2 γ x x ( τ ) d τ = 0 或 T → ∞ lim T 1 ∫ − T / 2 T / 2 r x x ( τ ) d τ = μ x 2
进一步,可证明以下情况是符合上述条件的,是广义平稳过程均值各态历经的充分 条件:
lim τ → ∞ γ x x ( τ ) = 0 或 lim τ → ∞ r x x ( τ ) = μ 2 \lim_{\tau\rightarrow \infty} \gamma_\mathbf{xx}(\tau) = 0 ~~~~~ \text{\small 或} ~~~~~ \lim_{\tau\rightarrow \infty} r_\mathbf{xx}(\tau) = \mu^2
τ → ∞ lim γ x x ( τ ) = 0 或 τ → ∞ lim r x x ( τ ) = μ 2
直观的,上述条件要求随机过程,在间隔时间足够长时,前后随机变量趋向不相关,这其实是一个很合理的要求。
Stochastic Processes
μ T = 1 T ∫ − T / 2 T / 2 x ( t ) d t , μ x = lim T → ∞ 1 T ∫ − T / 2 T / 2 x ( t ) d t = lim T → ∞ μ T \bm{\mu}_T = \frac{1}{T}\int_{-T/2}^{T/2} \mathbf{x}(t) dt, ~~~ \bm{\mu}_\mathbf{x} = \lim_{T\rightarrow\infty} \frac{1}{T}\int_{-T/2}^{T/2} \mathbf{x}(t) dt = \lim_{T\rightarrow\infty} \bm{\mu}_T
μ T = T 1 ∫ − T / 2 T / 2 x ( t ) d t , μ x = T → ∞ lim T 1 ∫ − T / 2 T / 2 x ( t ) d t = T → ∞ lim μ T
Var { μ T } = E { μ T 2 } − E 2 { μ T } = ∫ ∫ μ x 1 T μ x 2 T f ( x 1 , x 2 ) d x 1 d x 2 − ( ∫ μ x T f ( x ) d x ) 2 = ∫ ∫ d x 1 d x 2 ∫ − T / 2 T / 2 d t 1 T ∫ − T / 2 T / 2 d t 2 T x 1 ( t 1 ) x 2 ( t 2 ) f ( x 1 , x 2 ; t 1 , t 2 ) − ∫ d x 1 ∫ − T / 2 T / 2 d t 1 T x 1 ( t 1 ) f ( x 1 ; t 1 ) ∫ d x 2 ∫ − T / 2 T / 2 d t 2 T x 2 ( t 2 ) f ( x 2 ; t 2 ) = ∫ − T / 2 T / 2 d t 1 T ∫ − T / 2 T / 2 d t 2 T r x x ( t 1 , t 2 ) − ( ∫ − T / 2 T / 2 d t T μ x ( t ) ) 2 \begin{aligned}\text{Var}\{\bm{\mu}_T\} =& E\{ \bm{\mu}_T^2\} -E^2\{\bm{\mu}_T\}\\
=& \int\int \mu_{x_{1T}}\mu_{x_{2T}} f(x_1, x_2) dx_1 dx_2 - \left(\int \mu_{x_T} f(x) dx \right)^2 \\
=& \int\int dx_1 dx_2 \int_{-T/2}^{T/2}\frac{dt_1}{T} \int_{-T/2}^{T/2} \frac{dt_2}{T} ~ x_1(t_1)x_2(t_2) f(x_1, x_2; t_1, t_2) \\
&-\int dx_1 \int_{-T/2}^{T/2}\frac{dt_1}{T} ~ x_1(t_1)f(x_1; t_1) \int dx_2 \int_{-T/2}^{T/2} \frac{dt_2}{T} ~ x_2(t_2) f(x_2; t_2)\\
=& \int_{-T/2}^{T/2}\frac{dt_1}{T} \int_{-T/2}^{T/2} \frac{dt_2}{T} ~ r_{\mathbf{xx}}(t_1, t_2) - \left(\int_{-T/2}^{T/2} \frac{dt}{T} \mu_x(t)\right)^2
\end{aligned} Var { μ T } = = = = E { μ T 2 } − E 2 { μ T } ∫ ∫ μ x 1 T μ x 2 T f ( x 1 , x 2 ) d x 1 d x 2 − ( ∫ μ x T f ( x ) d x ) 2 ∫ ∫ d x 1 d x 2 ∫ − T / 2 T / 2 T d t 1 ∫ − T / 2 T / 2 T d t 2 x 1 ( t 1 ) x 2 ( t 2 ) f ( x 1 , x 2 ; t 1 , t 2 ) − ∫ d x 1 ∫ − T / 2 T / 2 T d t 1 x 1 ( t 1 ) f ( x 1 ; t 1 ) ∫ d x 2 ∫ − T / 2 T / 2 T d t 2 x 2 ( t 2 ) f ( x 2 ; t 2 ) ∫ − T / 2 T / 2 T d t 1 ∫ − T / 2 T / 2 T d t 2 r x x ( t 1 , t 2 ) − ( ∫ − T / 2 T / 2 T d t μ x ( t ) ) 2
对于广义平稳过程,r x x ( t 1 , t 2 ) = r x x ( t 1 − t 2 ) , μ x ( t ) = μ x r_{\mathbf{xx}}(t_1, t_2) = r_{\mathbf{xx}}(t_1-t_2), ~ \mu_x(t) = \mu_x r x x ( t 1 , t 2 ) = r x x ( t 1 − t 2 ) , μ x ( t ) = μ x
Var { μ T } = 1 T 2 ∫ − T / 2 T / 2 ∫ − T / 2 T / 2 d t 1 d t 2 r x x ( t 1 − t 2 ) − μ x 2 = 1 T 2 ∫ − T / 2 T / 2 d t ∫ − T 2 − t T 2 − t d τ γ x x ( τ ) = 1 T 2 ∫ 0 T d t ∫ − t T − t d τ γ x x ( τ ) = 1 T 2 ( ∫ − T 0 d τ γ x x ( τ ) ∫ − τ T d t + ∫ 0 T d τ γ x x ( τ ) ∫ 0 T − τ d t ) = 1 T 2 ∫ − T T d τ ( T − ∣ τ ∣ ) γ x x ( τ ) = 1 T 2 ∫ − T T d τ ( ∫ ∣ τ ∣ T d t ) γ x x ( τ ) = 1 T 2 ∫ 0 T d t ∫ − t t d τ γ x x ( τ ) lim T → ∞ 1 T ∫ − T / 2 T / 2 γ x x ( τ ) d τ = 0 ⇔ ∀ ϵ > 0 , ∃ T 0 , for t > T 0 , ∣ 1 2 t ∫ − t t γ x x ( τ ) d τ ∣ < ϵ ⇔ ∀ ϵ > 0 , ∃ T 0 , for t > T 0 , ∣ ∫ − t t γ x x ( τ ) d τ ∣ < 2 t ϵ Var { μ T } = 1 T 2 ( ∫ 0 T 0 d t ∫ − t t d τ γ x x ( τ ) + ∫ T 0 T d t ∫ − t t d τ γ x x ( τ ) ) ≤ 1 T 2 ∫ 0 T 0 d t ∫ − t t d τ ∣ γ x x ( τ ) ∣ + 1 T 2 ∫ T 0 T d t ∣ ∫ − t t d τ γ x x ( τ ) ∣ ≤ 1 T 2 ∫ 0 T 0 d t ∫ − t t d τ γ x x ( 0 ) + 1 T 2 ∫ T 0 T 2 t ϵ d t = T 0 2 T 2 γ x x ( 0 ) + T 2 − T 0 2 T 2 ϵ \begin{aligned}
\text{Var}\{\bm{\mu}_T\} =& \frac{1}{T^2}\int_{-T/2}^{T/2} \int_{-T/2}^{T/2} dt_1dt_2 ~ r_{\mathbf{xx}}(t_1-t_2) - \mu_x^2\\
=& \frac{1}{T^2}\int_{-T/2}^{T/2}dt \int_{-\frac{T}{2}-t}^{\frac{T}{2}-t} d\tau ~ \gamma_{\mathbf{xx}}(\tau)\\
=& \frac{1}{T^2}\int_{0}^{T}dt \int_{-t}^{T-t} d\tau ~ \gamma_{\mathbf{xx}}(\tau)\\
=& \frac{1}{T^2} \left(\int_{-T}^{0}d\tau ~ \gamma_{\mathbf{xx}}(\tau) \int_{-\tau}^{T} dt + \int_{0}^{T}d\tau ~ \gamma_{\mathbf{xx}}(\tau) \int_{0}^{T-\tau} dt\right)\\
=& \frac{1}{T^2} \int_{-T}^{T}d\tau ~ \bigl(T-|\tau|\bigr) ~ \gamma_{\mathbf{xx}}(\tau)\\
=& \frac{1}{T^2} \int_{-T}^{T}d\tau ~ \left(\int^{T}_{|\tau|} dt\right) ~ \gamma_{\mathbf{xx}}(\tau)\\
=& \frac{1}{T^2} \int_{0}^{T} dt \int_{-t}^{t} d\tau ~ \gamma_{\mathbf{xx}}(\tau) \\
\lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} & \gamma_\mathbf{xx}(\tau) d\tau = 0 \\
\Leftrightarrow& \forall \epsilon>0, ~ \exists T_0, ~ \text{for} ~ t>T_0, \left|\frac{1}{2t}\int_{-t}^{t} \gamma_\mathbf{xx}(\tau) d\tau\right| < \epsilon\\
\Leftrightarrow& \forall \epsilon>0, ~ \exists T_0, ~ \text{for} ~ t>T_0, \left|\int_{-t}^{t} \gamma_\mathbf{xx}(\tau) d\tau\right| < 2t\epsilon\\
\text{Var}\{\bm{\mu}_T\} =& \frac{1}{T^2} \left( \int_{0}^{T_0} dt \int_{-t}^{t} d\tau ~ \gamma_{\mathbf{xx}}(\tau) + \int_{T_0}^{T} dt \int_{-t}^{t} d\tau ~ \gamma_{\mathbf{xx}}(\tau) \right)\\
\le& \frac{1}{T^2} \int_{0}^{T_0} dt \int_{-t}^{t} d\tau ~ |\gamma_{\mathbf{xx}}(\tau)| + \frac{1}{T^2} \int_{T_0}^{T} dt \left|\int_{-t}^{t} d\tau ~ \gamma_{\mathbf{xx}}(\tau)\right|\\
\le& \frac{1}{T^2} \int_{0}^{T_0} dt \int_{-t}^{t} d\tau ~ \gamma_{\mathbf{xx}}(0) + \frac{1}{T^2} \int_{T_0}^{T} 2t\epsilon ~ dt\\
=& \frac{T_0^2}{T^2} \gamma_{\mathbf{xx}}(0) + \frac{T^2-T_0^2}{T^2}\epsilon
\end{aligned} Var { μ T } = = = = = = = T → ∞ lim T 1 ∫ − T / 2 T / 2 ⇔ ⇔ Var { μ T } = ≤ ≤ = T 2 1 ∫ − T / 2 T / 2 ∫ − T / 2 T / 2 d t 1 d t 2 r x x ( t 1 − t 2 ) − μ x 2 T 2 1 ∫ − T / 2 T / 2 d t ∫ − 2 T − t 2 T − t d τ γ x x ( τ ) T 2 1 ∫ 0 T d t ∫ − t T − t d τ γ x x ( τ ) T 2 1 ( ∫ − T 0 d τ γ x x ( τ ) ∫ − τ T d t + ∫ 0 T d τ γ x x ( τ ) ∫ 0 T − τ d t ) T 2 1 ∫ − T T d τ ( T − ∣ τ ∣ ) γ x x ( τ ) T 2 1 ∫ − T T d τ ( ∫ ∣ τ ∣ T d t ) γ x x ( τ ) T 2 1 ∫ 0 T d t ∫ − t t d τ γ x x ( τ ) γ x x ( τ ) d τ = 0 ∀ ϵ > 0 , ∃ T 0 , for t > T 0 , ∣ ∣ ∣ ∣ ∣ 2 t 1 ∫ − t t γ x x ( τ ) d τ ∣ ∣ ∣ ∣ ∣ < ϵ ∀ ϵ > 0 , ∃ T 0 , for t > T 0 , ∣ ∣ ∣ ∣ ∣ ∫ − t t γ x x ( τ ) d τ ∣ ∣ ∣ ∣ ∣ < 2 t ϵ T 2 1 ( ∫ 0 T 0 d t ∫ − t t d τ γ x x ( τ ) + ∫ T 0 T d t ∫ − t t d τ γ x x ( τ ) ) T 2 1 ∫ 0 T 0 d t ∫ − t t d τ ∣ γ x x ( τ ) ∣ + T 2 1 ∫ T 0 T d t ∣ ∣ ∣ ∣ ∣ ∫ − t t d τ γ x x ( τ ) ∣ ∣ ∣ ∣ ∣ T 2 1 ∫ 0 T 0 d t ∫ − t t d τ γ x x ( 0 ) + T 2 1 ∫ T 0 T 2 t ϵ d t T 2 T 0 2 γ x x ( 0 ) + T 2 T 2 − T 0 2 ϵ
∀ ϵ > 0 , Var { μ x } = lim T → ∞ Var { μ T } ≤ ϵ ⇒ Var { μ x } = 0 \forall \epsilon>0, ~ \text{Var}\{\bm{\mu}_\mathbf{x}\} = \lim_{T\rightarrow\infty} \text{Var}\{\bm{\mu}_T\} \le \epsilon ~~~ \Rightarrow ~~~ \text{Var}\{\bm{\mu}_\mathbf{x}\}=0
∀ ϵ > 0 , Var { μ x } = T → ∞ lim Var { μ T } ≤ ϵ ⇒ Var { μ x } = 0
其他特殊过程
随机过程x ( t ) \mathbf{x}(t) x ( t ) t t t F ( x ; t ) F(x; t) F ( x ; t )
两个随机过程的正交、独立和不相关:
不相关:不同时刻互协方差为零 ∀ t 1 ≠ t 2 , γ x y ( t 1 , t 2 ) = 0 \forall t_1 \neq t_2, \gamma_\mathbf{xy}(t_1, t_2)=0 ∀ t 1 = t 2 , γ x y ( t 1 , t 2 ) = 0 r x y ( t 1 , t 2 ) = μ x ( t 1 ) μ y ( t 2 ) ~~~~r_\mathbf{xy}(t_1, t_2)=\mu_\mathbf{x}(t_1)\mu_\mathbf{y}(t_2) r x y ( t 1 , t 2 ) = μ x ( t 1 ) μ y ( t 2 )
正交:不同时刻互相关为零 ∀ t 1 ≠ t 2 , r x y ( t 1 , t 2 ) = 0 \forall t_1 \neq t_2, r_\mathbf{xy}(t_1, t_2)=0 ∀ t 1 = t 2 , r x y ( t 1 , t 2 ) = 0
独立:联合分布为逐点分布之积∀ n , m , f ( x 1 , . . . , x n , y 1 , . . . , y m ; t 1 , . . . , t n , t 1 ′ , . . . , t m ′ ) = ∏ l f ( x k ; t k ) ∏ l f ( y l ; t l ′ ) \small \forall n, m, f(x_1, ..., x_n, y_1, ..., y_m; t_1, ..., t_n, t'_1, ..., t'_m ) = \prod_l f(x_k; t_k)\prod_l f(y_l; t'_l) ∀ n , m , f ( x 1 , . . . , x n , y 1 , . . . , y m ; t 1 , . . . , t n , t 1 ′ , . . . , t m ′ ) = ∏ l f ( x k ; t k ) ∏ l f ( y l ; t l ′ )
类似的,根据自相关/自协方差可定义单个随机过程的不相关、正交与独立等概念
不相关/正交/独立增量过程:增量∀ t k , x ( t k ) - x ( t k + 1 ) \forall t_k,\mathbf{x}(t_k)\text{-}\mathbf{x}(t_{k+1}) ∀ t k , x ( t k ) - x ( t k + 1 )
独立同分布(i.i.d.)过程:∀ t , f ( x ; t ) \forall t, f(x; t) ∀ t , f ( x ; t )
高斯过程 ∀ n , f ( x 1 , . . . , x n ; t 1 , . . . , t n ) \forall n, f(x_1, ..., x_n; t_1, ..., t_n) ∀ n , f ( x 1 , . . . , x n ; t 1 , . . . , t n ) f ( x ; t ) f(x;t) f ( x ; t ) μ ( t ) \mu(t) μ ( t ) r x x ( t 1 , t 2 ) r_\mathbf{xx}(t_1, t_2) r x x ( t 1 , t 2 )
相关与功率谱
对于确定性函数,可通过傅里叶变换进行频域分解,而随机过程可视为无数具体实现组成的系综,原则上可以对其具体的实现进行傅里叶变换。但由于任意t t t x ( t ) \mathbf{x}(t) x ( t ) t → ∞ t\rightarrow\infty t → ∞
功率谱定义
为获取频谱可参照确定性函数的功率谱,针对随机过程的具体实现定义功率谱,但一般地该功率谱是随机的,不同实现的功率谱不同,需进一步对其求期望:
S ( f ) = lim T → ∞ 1 T E { ∣ X T ( f ) ∣ 2 } S(f) = \lim_{T\rightarrow\infty} \frac{1}{T} E\left\{ |\mathbf{X}_T(f)|^2 \right\}
S ( f ) = T → ∞ lim T 1 E { ∣ X T ( f ) ∣ 2 }
在实际计算上,原则上可进行大量重复试验,对于每次试验得到的具体信号,截取有限时间区间计算功率谱1 T ∣ X T ( f ) ∣ 2 \frac{1}{T} |X_T(f)|^2 T 1 ∣ X T ( f ) ∣ 2
除了分析随机过程的具体实现,另一个角度是分析随机过程的统计量,后者是确定性的函数。具体的,对于广义平稳过程,其均值为常数,没有分析的价值,而自相关作为时间差的函数,根据维纳-辛钦定理(Wiener–Khinchin theorem)有:
r x x ( τ ) = E { x ( t ) x ( t + τ ) } = ∫ S ( f ) e i 2 π f τ d f = F − 1 { S ( f ) } r_\mathbf{xx}(\tau) = E\big\{ \mathbf{x}(t)\mathbf{x}(t+\tau) \big\} = \int S(f) e^{i 2 \pi f \tau} df = \mathcal{F}^{-1}\{ S(f) \}
r x x ( τ ) = E { x ( t ) x ( t + τ ) } = ∫ S ( f ) e i 2 π f τ d f = F − 1 { S ( f ) }
即对于广义平稳过程的自相关函数,存在频域的对应S ( f ) S(f) S ( f )
S ( f ) = F { r x x ( τ ) } = ∫ r x x ( τ ) e − i 2 π f τ d τ \boxed{S(f) = \mathcal{F}\{ r_\mathbf{xx}(\tau) \} = \int r_\mathbf{xx}(\tau) e^{-i 2 \pi f \tau} d\tau}
S ( f ) = F { r x x ( τ ) } = ∫ r x x ( τ ) e − i 2 π f τ d τ
上述关系对所有广义平稳过程成立,而对于自相关各态历经过程有r x x ( τ ) = r x x ( τ ) r_\mathbf{xx}(\tau) = r_{xx}(\tau) r x x ( τ ) = r x x ( τ )
S ( f ) = F { r x x ( τ ) } = F { r x x ( τ ) } = F { lim T → ∞ 1 T ∫ − T / 2 T / 2 x ( t ) x ( t + τ ) d t } = lim T → ∞ 1 T F { x T ( t ) ⋆ x T ( t ) } = lim T → ∞ 1 T ∣ X T ( f ) ∣ 2 \begin{aligned}
S(f) = \mathcal{F}\{ r_\mathbf{xx}(\tau) \} &= \mathcal{F}\{ r_{xx}(\tau) \} \\
&= \mathcal{F}\left\{ \lim_{T\rightarrow \infty} \frac{1}{T}\int_{-T/2}^{T/2} x(t)x(t+\tau) dt \right\}\\
&= \lim_{T\rightarrow \infty} \frac{1}{T} ~ \mathcal{F}\left\{ x_T(t) \star x_T(t)\right\}\\
&= \lim_{T\rightarrow \infty} \frac{1}{T} ~ |X_T(f)|^2
\end{aligned} S ( f ) = F { r x x ( τ ) } = F { r x x ( τ ) } = F { T → ∞ lim T 1 ∫ − T / 2 T / 2 x ( t ) x ( t + τ ) d t } = T → ∞ lim T 1 F { x T ( t ) ⋆ x T ( t ) } = T → ∞ lim T 1 ∣ X T ( f ) ∣ 2
基于自相关各态历经,计算随机过程的功率谱F { r x x ( τ ) } \mathcal{F}\{ r_\mathbf{xx}(\tau) \} F { r x x ( τ ) } F { r x x ( τ ) } = lim T → ∞ 1 T ∣ X T ( f ) ∣ 2 \mathcal{F}\{ r_{xx}(\tau) \} = \lim_{T\rightarrow \infty} \frac{1}{T} ~ |X_T(f)|^2 F { r x x ( τ ) } = lim T → ∞ T 1 ∣ X T ( f ) ∣ 2
功率谱为实对称函数S ( − f ) = S ( f ) S(-f) = S(f) S ( − f ) = S ( f ) S ( f ) ≥ 0 S(f) \ge 0 S ( f ) ≥ 0 r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ ) 正定性 ,正定函数是作为自相关函数的充要条件。其定义为对任意的x 1 , . . . , x n ∈ R x_1, ..., x_n \in \R x 1 , . . . , x n ∈ R f ( x i − x j ) f(x_i-x_j) f ( x i − x j )
对功率谱积分对应随机过程平均功率 r x x ( 0 ) = E { x 2 ( t ) } = ∫ S ( f ) d f r_\mathbf{xx}(0) = E\left\{ \mathbf{x}^2(t) \right\} = \int S(f) df r x x ( 0 ) = E { x 2 ( t ) } = ∫ S ( f ) d f σ 2 \sigma^2 σ 2 S ( 0 ) = ∫ r x x ( τ ) d τ = μ 2 δ ( f ) S(0) = \int r_\mathbf{xx}(\tau) d\tau = \mu^2\delta(f) S ( 0 ) = ∫ r x x ( τ ) d τ = μ 2 δ ( f )
最后,对于广义联合平稳的两个随机过程,基于互相关函数可定义互功率谱。互功率谱并不一定为实函数S x y ( − f ) = S x y ( f ) ‾ = S y x ( f ) S_\mathbf{xy}(-f) = \overline{S_\mathbf{xy}(f)} = S_\mathbf{yx}(f) S x y ( − f ) = S x y ( f ) = S y x ( f )
自相关与功率谱的直观理解
数学上,自相关为间隔τ \tau τ r x x ( τ ) = E { x ( t ) x ( t + τ ) } r_\mathbf{xx}(\tau) = E\big\{ \mathbf{x}(t)\mathbf{x}(t+\tau) \big\} r x x ( τ ) = E { x ( t ) x ( t + τ ) } τ \tau τ
r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ ) τ \tau τ r x x ( τ ) r_\mathbf{xx}(\tau) r x x ( τ ) τ \tau τ
均值为0时lim τ → ∞ r x x ( τ ) = 0 \lim_{\tau\rightarrow \infty} r_\mathbf{xx}(\tau)=0 lim τ → ∞ r x x ( τ ) = 0 r x x ( 0 ) ≥ ∣ r x x ( τ ) ∣ r_\mathbf{xx}(0) \ge |r_\mathbf{xx}(\tau)| r x x ( 0 ) ≥ ∣ r x x ( τ ) ∣
直观地,假设x ( t ) \mathbf{x}(t) x ( t ) y ( t ) \mathbf{y}(t) y ( t ) f ( x ; t ) f(x;t) f ( x ; t ) x ( t ) \mathbf{x}(t) x ( t ) τ \tau τ τ \tau τ x ( t ) \mathbf{x}(t) x ( t )
事实上,对于随机过程,自相关函数能够检测出原始信号内部蕴藏的周期组分。以初始相位随机的正弦波动为例,x ( t ) = sin ( ω t + ϕ ) \mathbf{x}(t)=\sin(\omega t + \bm{\phi}) x ( t ) = sin ( ω t + ϕ ) ϕ \bm{\phi} ϕ [ 0 , 2 π ] [0, 2\pi] [ 0 , 2 π ]
功率谱估计
平稳随机过程自相关函数是确定的,相应的功率谱也是确定的,但现实中观测数据是有限的,无法得到完整的自相关函数,只能用有限的数据对目标功率谱进行估计。具体方法上分两大类:以傅里叶变换为基础、非参数化的经典谱估计,以及以参数化模型为基础的现代谱估计。
经典谱估计中,观测数据之外直接视为零(或理解为周期性延拓),受限于数据长度,频率分辨率有限,且存在偏置(谱泄露)。而考虑到数据中的随机噪声,经典谱估计还存在较大的方差,需要专门措施来补救。现代谱估计的出现点是基于数据内部关联性建立模型,合理外推,打破数据长度的限制,改善谱估计的分辨率和方差,最常见的是自回归AR模型。
经典谱估计 :以FT为基础、非参数化、线性
直接法:周期图法及其改进
周期图(Periodogram):1 N f s ∣ X k ∣ 2 \frac{1}{N f_s}\left|X_k\right|^2 N f s 1 ∣ X k ∣ 2
平均周期图(Bartlett’s method):对数据切片,功率谱求平均
加窗平均周期图(Welch’s method):对数据片段加窗,允许重叠
多窗口法(Multitaper method, MTM):多个(正交)窗口,功率谱求平均
非均匀采样:Lomb-Scargle周期图
间接法:自相关方法(Blackman-Tukey method)
现代谱估计 :基于模型、(半)参数化、非线性S ( f ; θ 1 , … , θ p ) S(f; \theta_1, \ldots , \theta_p) S ( f ; θ 1 , … , θ p )
无偏估计与一致估计 μ ^ \hat{\mu} μ ^ μ \mu μ μ ^ \hat{\mu} μ ^ E { μ ^ } E\{\hat{\mu}\} E { μ ^ } μ \mu μ σ μ ^ 2 = E { ( μ ^ − E { μ ^ } ) 2 } = E { μ ^ 2 } − E { μ ^ } 2 \sigma_{\hat{\mu}}^2 = E\{(\hat{\mu} - E\{\hat{\mu}\})^2\} = E\{\hat{\mu}^2\} - E\{\hat{\mu}\}^2 σ μ ^ 2 = E { ( μ ^ − E { μ ^ } ) 2 } = E { μ ^ 2 } − E { μ ^ } 2 μ ^ \hat{\mu} μ ^ μ \mu μ b = μ − E { μ ^ } b = \mu-E\{\hat{\mu}\} b = μ − E { μ ^ } M S E ( μ ^ ) = E { ( μ ^ − μ ) 2 } = b 2 + σ μ ^ 2 {\rm MSE}(\hat{\mu}) = E\{(\hat{\mu} - \mu)^2\} = b^2 + \sigma_{\hat{\mu}}^2 M S E ( μ ^ ) = E { ( μ ^ − μ ) 2 } = b 2 + σ μ ^ 2
若b = 0 , E { μ ^ } = μ b=0, E\{\hat{\mu}\} = \mu b = 0 , E { μ ^ } = μ μ ^ \hat{\mu} μ ^ μ \mu μ M S E ( μ ^ ) = 0 {\rm MSE}(\hat{\mu}) = 0 M S E ( μ ^ ) = 0 μ ^ \hat{\mu} μ ^ μ \mu μ N N N lim N → ∞ E { μ ^ N } = μ \lim_{N\rightarrow\infty} E\{\hat{\mu}_N\} = \mu lim N → ∞ E { μ ^ N } = μ μ ^ N \hat{\mu}_N μ ^ N μ \mu μ lim N → ∞ M S E ( μ ^ N ) = 0 \lim_{N\rightarrow\infty} {\rm MSE}(\hat{\mu}_N) = 0 lim N → ∞ M S E ( μ ^ N ) = 0 μ ^ N \hat{\mu}_N μ ^ N μ \mu μ
自相关函数估计
r x x ( τ ) = E [ x ( t ) x ( t + τ ) ] = r x x ( τ ) = lim T → ∞ 1 2 T ∫ − T T x ( t ) x ( t + τ ) d t r_\mathbf{xx}(\tau) = E[\mathbf{x}(t)\mathbf{x}(t+\tau)] = r_{xx}(\tau) = \lim_{T\rightarrow \infty} \frac{1}{2T}\int_{-T}^{T} x(t)x(t+\tau) dt
r x x ( τ ) = E [ x ( t ) x ( t + τ ) ] = r x x ( τ ) = T → ∞ lim 2 T 1 ∫ − T T x ( t ) x ( t + τ ) d t
对于离散随机过程:
r x x [ k ] = r x x [ k ] = lim N → ∞ 1 N ∑ n = 0 N − 1 x [ n ] x [ n + k ] = lim N → ∞ E { r N [ k ] } r_\mathbf{xx}[k] = r_{xx}[k] = \lim_{N\rightarrow \infty} \frac{1}{N}\sum_{n=0}^{N-1} x[n]x[n+k] = \lim_{N\rightarrow \infty} E\{\mathbf{r}_N[k]\}
r x x [ k ] = r x x [ k ] = N → ∞ lim N 1 n = 0 ∑ N − 1 x [ n ] x [ n + k ] = N → ∞ lim E { r N [ k ] }
其中r N [ k ] \mathbf{r}_N[k] r N [ k ]
r N [ k ] = 1 N ∑ n = 0 N − 1 x [ n ] x [ n + k ] , ∣ k ∣ ≤ N − 1 \mathbf{r}_N[k] = \frac{1}{N}\sum_{n=0}^{N-1} \mathbf{x}[n]\mathbf{x}[n+k], ~~ |k| \le N-1
r N [ k ] = N 1 n = 0 ∑ N − 1 x [ n ] x [ n + k ] , ∣ k ∣ ≤ N − 1
注意,这里会出现指标越界,此时值取零(补零延拓),等价的也可表示为:
r N [ k ] = 1 N ∑ n = 0 N − ∣ k ∣ − 1 x [ n ] x [ n + ∣ k ∣ ] , ∣ k ∣ ≤ N − 1 \mathbf{r}_N[k] = \frac{1}{N}\sum_{n=0}^{N-|k|-1} \mathbf{x}[n]\mathbf{x}[n+|k|], ~~ |k| \le N-1
r N [ k ] = N 1 n = 0 ∑ N − ∣ k ∣ − 1 x [ n ] x [ n + ∣ k ∣ ] , ∣ k ∣ ≤ N − 1
对上述表达式求期望有:
E { r N [ k ] } = 1 N ∑ n = 0 N − ∣ k ∣ − 1 E { x [ n ] x [ n + ∣ k ∣ ] } = N − ∣ k ∣ N r x x [ k ] , ∣ k ∣ ≤ N − 1 E\{\mathbf{r}_N[k]\} = \frac{1}{N}\sum_{n=0}^{N-|k|-1} E\{\mathbf{x}[n]\mathbf{x}[n+|k|]\} = \frac{N-|k|}{N} r_\mathbf{xx}[k], ~~ |k| \le N-1
E { r N [ k ] } = N 1 n = 0 ∑ N − ∣ k ∣ − 1 E { x [ n ] x [ n + ∣ k ∣ ] } = N N − ∣ k ∣ r x x [ k ] , ∣ k ∣ ≤ N − 1
可见r N [ k ] \mathbf{r}_N[k] r N [ k ] lim N → ∞ r N [ k ] = r x x [ k ] \lim_{N\rightarrow\infty}\mathbf{r}_N[k] = r_\mathbf{xx}[k] lim N → ∞ r N [ k ] = r x x [ k ] r x x [ k ] r_\mathbf{xx}[k] r x x [ k ]
r N ′ [ k ] = 1 N − ∣ k ∣ ∑ n = 0 N − ∣ k ∣ − 1 x [ n ] x [ n + ∣ k ∣ ] , ∣ k ∣ ≤ N − 1 \mathbf{r}'_N[k] = \frac{1}{N-|k|}\sum_{n=0}^{N-|k|-1} \mathbf{x}[n]\mathbf{x}[n+|k|], ~~ |k| \le N-1
r N ′ [ k ] = N − ∣ k ∣ 1 n = 0 ∑ N − ∣ k ∣ − 1 x [ n ] x [ n + ∣ k ∣ ] , ∣ k ∣ ≤ N − 1
但注意σ r N ′ 2 = ( N N − ∣ k ∣ ) 2 σ r N 2 \sigma^2_{\mathbf{r}'_N} = \left(\frac{N}{N-|k|}\right)^2\sigma^2_{\mathbf{r}_N} σ r N ′ 2 = ( N − ∣ k ∣ N ) 2 σ r N 2
自相关法频谱估计
S N [ k ] = F { r N [ m ] } \mathbf{S}_N[k] = \mathcal{F}\{ \mathbf{r}_N[m]\}
S N [ k ] = F { r N [ m ] }
E { S N [ f k ] } = F { E { r N [ m ] } } = F { N − ∣ m ∣ N r x x [ m ] } , ∣ m ∣ ≤ N − 1 E\{\mathbf{S}_N[f_k]\} = \mathcal{F}\left\{ E\{\mathbf{r}_N[m]\}\right\} = \mathcal{F}\left\{ \frac{N-|m|}{N} r_\mathbf{xx}[m]\right\}, ~~ |m| \le N-1
E { S N [ f k ] } = F { E { r N [ m ] } } = F { N N − ∣ m ∣ r x x [ m ] } , ∣ m ∣ ≤ N − 1
r N [ k ] \mathbf{r}_N[k] r N [ k ] r x x [ k ] r_\mathbf{xx}[k] r x x [ k ] [ − ( N − 1 ) , N − 1 ] \small [-(N-1), N-1] [ − ( N − 1 ) , N − 1 ]
w N [ m ] = { N − ∣ m ∣ N if ∣ m ∣ ≤ N − 1 0 others w_N[m] = \begin{cases} \frac{N-|m|}{N} & \text{if} ~~ |m| \le N-1\\
0 & \text{others} \end{cases} w N [ m ] = { N N − ∣ m ∣ 0 if ∣ m ∣ ≤ N − 1 others
E { S N [ f k ] } = F { w N [ m ] r x x [ m ] } = 1 f s F N ( 2 π f f s ) ∗ S ( f ) , f ∈ [ − f s 2 , f s 2 ) E\{\mathbf{S}_N[f_k]\} = \mathcal{F}\left\{w_N[m] r_\mathbf{xx}[m]\right\} = \frac{1}{f_s} F_N\left(\frac{2\pi f}{f_s}\right)*S(f), ~~~ f\in[-\frac{f_s}{2}, \frac{f_s}{2})
E { S N [ f k ] } = F { w N [ m ] r x x [ m ] } = f s 1 F N ( f s 2 π f ) ∗ S ( f ) , f ∈ [ − 2 f s , 2 f s )
注意这里S ( f ) S(f) S ( f ) [ − f s 2 , f s 2 ) [-\frac{f_s}{2}, \frac{f_s}{2}) [ − 2 f s , 2 f s ) w N [ m ] w_N[m] w N [ m ] F N ( f ) F_N(f) F N ( f ) F N ( x ) = sin 2 ( N 2 x ) N sin 2 ( 1 2 x ) F_N(x)=\frac{\sin^2(\frac{N}{2} x)}{N\sin^2(\frac{1}{2}x)} F N ( x ) = N s i n 2 ( 2 1 x ) s i n 2 ( 2 N x ) 2 π 2\pi 2 π s i n c 2 \rm sinc^2 s i n c 2
类似的,基于自相关的无偏估计r ′ N [ m ] \mathbf{r'}_N[m] r ′ N [ m ]
E { S ′ N [ k ] } = F { w N ′ [ m ] r x x [ m ] } = 1 f s D N ( 2 π f f s ) ∗ S ( f ) , f ∈ [ − f s 2 , f s 2 ) E\{\mathbf{S'}_N[k]\} = \mathcal{F}\{ w'_N[m] r_\mathbf{xx}[m]\} = \frac{1}{f_s} D_N\left(\frac{2\pi f}{f_s}\right)*S(f), ~~~ f\in[-\frac{f_s}{2}, \frac{f_s}{2})
E { S ′ N [ k ] } = F { w N ′ [ m ] r x x [ m ] } = f s 1 D N ( f s 2 π f ) ∗ S ( f ) , f ∈ [ − 2 f s , 2 f s )
其中w N ′ [ m ] w'_N[m] w N ′ [ m ] [ − ( N − 1 ) , N − 1 ] \small [-(N-1),N-1] [ − ( N − 1 ) , N − 1 ] D N ( f ) D_N(f) D N ( f ) D N ( x ) = sin ( 2 N + 1 2 x ) sin ( 1 2 x ) D_N(x)=\frac{\sin(\frac{2N+1}{2}x)}{\sin(\frac{1}{2}x)} D N ( x ) = s i n ( 2 1 x ) s i n ( 2 2 N + 1 x ) 2 π 2\pi 2 π s i n c \rm sinc s i n c r ′ N [ m ] \mathbf{r'}_N[m] r ′ N [ m ]
两种谱估计都是有偏的,但当N → ∞ N\rightarrow\infty N → ∞ F N ( f ) F_N(f) F N ( f ) D N ( f ) D_N(f) D N ( f ) 2 π 2\pi 2 π S ( f ) , f ∈ [ − f s 2 , f s 2 ) S(f), f\in[-\frac{f_s}{2}, \frac{f_s}{2}) S ( f ) , f ∈ [ − 2 f s , 2 f s )
周期图法 v.s. 自相关法
S N ( P ) [ k ] = 1 N f s ∣ ∑ n = 0 N − 1 x n e − i 2 π k N n ∣ 2 = 1 N f s ∑ p = 0 N − 1 ∑ q = 0 N − 1 x p e − i 2 π k N p ‾ x q e − i 2 π k N q = 1 N f s ∑ p = 0 N − 1 ∑ q = 0 N − 1 x p x q e − i 2 π k N ( q − p ) = 1 f s ∑ m = − ( N − 1 ) N − 1 1 N ∑ p = 0 N − ∣ m ∣ − 1 x p x p + ∣ m ∣ e − i 2 π k N m = 1 f s ∑ m = − ( N − 1 ) N − 1 r N [ m ] e − i 2 π k N m = F { r N [ m ] } = S N [ k ] \begin{aligned}
\mathbf{S}_N^{(P)}[k] &= \frac{1}{Nf_s} \left|\sum_{n=0}^{N-1} \mathbf{x}_n e^{-i \frac{2\pi k}{N} n}\right|^2
= \frac{1}{Nf_s} \sum_{p=0}^{N-1}\sum_{q=0}^{N-1} \overline{\mathbf{x}_p e^{-i \frac{2\pi k}{N} p}} \mathbf{x}_q e^{-i \frac{2\pi k}{N} q}\\
&= \frac{1}{Nf_s} \sum_{p=0}^{N-1}\sum_{q=0}^{N-1} \mathbf{x}_p \mathbf{x}_q e^{-i \frac{2\pi k}{N} (q-p)}\\
&= \frac{1}{f_s} \sum_{m=-(N-1)}^{N-1} \frac{1}{N}\sum_{p=0}^{N-|m|-1} \mathbf{x}_p \mathbf{x}_{p+|m|} ~~ e^{-i \frac{2\pi k}{N} m}\\
&= \frac{1}{f_s} \sum_{m=-(N-1)}^{N-1} \mathbf{r}_N[m] ~ e^{-i \frac{2\pi k}{N} m}\\
&= \mathcal{F}\{\mathbf{r}_N[m]\} = \mathbf{S}_N[k]
\end{aligned} S N ( P ) [ k ] = N f s 1 ∣ ∣ ∣ ∣ ∣ ∣ n = 0 ∑ N − 1 x n e − i N 2 π k n ∣ ∣ ∣ ∣ ∣ ∣ 2 = N f s 1 p = 0 ∑ N − 1 q = 0 ∑ N − 1 x p e − i N 2 π k p x q e − i N 2 π k q = N f s 1 p = 0 ∑ N − 1 q = 0 ∑ N − 1 x p x q e − i N 2 π k ( q − p ) = f s 1 m = − ( N − 1 ) ∑ N − 1 N 1 p = 0 ∑ N − ∣ m ∣ − 1 x p x p + ∣ m ∣ e − i N 2 π k m = f s 1 m = − ( N − 1 ) ∑ N − 1 r N [ m ] e − i N 2 π k m = F { r N [ m ] } = S N [ k ]
对连续谱S ( f ) = ∫ r ( τ ) e − i 2 π f τ d τ S(f)=\int r(\tau) e^{-i2\pi f \tau} d\tau S ( f ) = ∫ r ( τ ) e − i 2 π f τ d τ 1 f s \frac{1}{f_s} f s 1 d τ d\tau d τ
当然这种“等价”是有条件的。一方面,长度2 N + 1 2N+1 2 N + 1 f s 2 N + 1 \frac{f_s}{2N+1} 2 N + 1 f s f s N \frac{f_s}{N} N f s F N ( f ) F_N(f) F N ( f )
S N [ k ] = 1 f s ∑ m = − ( M − 1 ) M − 1 r N [ m ] e − i 2 π k N m \mathbf{S}_N[k] = \frac{1}{f_s} \sum_{m=-(M-1)}^{M-1} \mathbf{r}_N[m] ~ e^{-i \frac{2\pi k}{N} m}
S N [ k ] = f s 1 m = − ( M − 1 ) ∑ M − 1 r N [ m ] e − i N 2 π k m
这里M < N − 1 \small M<N-1 M < N − 1 f s N \frac{f_s}{N} N f s f s M \frac{f_s}{M} M f s m m m r N [ m ] \mathbf{r}_N[m] r N [ m ] r N [ N − 1 ] = 1 N x [ 0 ] x [ N − 1 ] \mathbf{r}_N[N-1] = \frac{1}{N}x[0]x[N-1] r N [ N − 1 ] = N 1 x [ 0 ] x [ N − 1 ] m m m
E { S N [ k ] } = S ( f ) ∗ 1 f s F N ( 2 π f f s ) ∗ 1 f s D M ( 2 π f f s ) , f ∈ [ − f s 2 , f s 2 ) E\{\mathbf{S}_N[k]\} = S(f)*\frac{1}{f_s} F_N\left(\frac{2\pi f}{f_s}\right)*\frac{1}{f_s}D_M\left(\frac{2\pi f}{f_s}\right), ~~~ f\in[-\frac{f_s}{2}, \frac{f_s}{2})
E { S N [ k ] } = S ( f ) ∗ f s 1 F N ( f s 2 π f ) ∗ f s 1 D M ( f s 2 π f ) , f ∈ [ − 2 f s , 2 f s )
在N → ∞ , M → ∞ \small N\rightarrow \infty, M\rightarrow \infty N → ∞ , M → ∞ σ S N 2 ∼ M N S 2 ( f ) \sigma^2_{\mathbf{S}_N} \sim \frac{M}{N} S^2(f) σ S N 2 ∼ N M S 2 ( f ) M M M M M M M , N M M, \frac{N}{M} M , M N
而对于加窗的周期图法(时间序列直接加窗):
E { S N ( P ) [ k ] } = 1 N f s ∑ p = 0 N − 1 ∑ q = 0 N − 1 w p w q E { x p x q } e − i 2 π k N ( q − p ) = 1 N f s ∑ p = 0 N − 1 ∑ q = 0 N − 1 w p w q r x x ( q − p ) e − i 2 π k N ( q − p ) = 1 f s ∑ m = − ( N − 1 ) N − 1 1 N ∑ n = 0 N − ∣ m ∣ − 1 w n w n + ∣ m ∣ r x x ( m ) e − i 2 π k N m = F { w n ∗ w n N r x x ( m ) } = ∣ W N ( f ) ∣ 2 ∗ S ( f ) \begin{aligned}
E\{\mathbf{S}_N^{(P)}[k]\} &= \frac{1}{Nf_s} \sum_{p=0}^{N-1}\sum_{q=0}^{N-1} w_p w_q ~~ E\{\mathbf{x}_p \mathbf{x}_q\} ~~ e^{-i \frac{2\pi k}{N} (q-p)}\\
&= \frac{1}{Nf_s} \sum_{p=0}^{N-1}\sum_{q=0}^{N-1} w_p w_q ~~ r_\mathbf{xx}(q-p) ~~ e^{-i \frac{2\pi k}{N} (q-p)}\\
& = \frac{1}{f_s} \sum_{m=-(N-1)}^{N-1} ~~ \frac{1}{N}\sum_{n=0}^{N-|m|-1} w_n w_{n+|m|} ~~ r_\mathbf{xx}(m) e^{-i \frac{2\pi k}{N} m}\\
& = \mathcal{F}\left\{ \frac{w_n * w_n}{N} ~ r_\mathbf{xx}(m)\right\} = |W_N(f)|^2 * S(f)
\end{aligned} E { S N ( P ) [ k ] } = N f s 1 p = 0 ∑ N − 1 q = 0 ∑ N − 1 w p w q E { x p x q } e − i N 2 π k ( q − p ) = N f s 1 p = 0 ∑ N − 1 q = 0 ∑ N − 1 w p w q r x x ( q − p ) e − i N 2 π k ( q − p ) = f s 1 m = − ( N − 1 ) ∑ N − 1 N 1 n = 0 ∑ N − ∣ m ∣ − 1 w n w n + ∣ m ∣ r x x ( m ) e − i N 2 π k m = F { N w n ∗ w n r x x ( m ) } = ∣ W N ( f ) ∣ 2 ∗ S ( f )
对应于自相关法,相当于对无偏的自相关估计加以下延迟窗:
w N ′ = 1 N w N ⋆ w N = 1 N w N ∗ w N w'_N = \frac{1}{N} w_N\star w_N = \frac{1}{N} w_N*w_N
w N ′ = N 1 w N ⋆ w N = N 1 w N ∗ w N
最简单的,时间序列的矩形窗对应于自相关的三角窗。
可以看到虽然在一定条件下,自相关法与周期图法等价,但两者还是有区别的,尤其是考虑到对自相关加窗是不同于时序信号直接加窗的,前者限制的是计算自相关时的提前或滞后量,而非时序信号长度,也被称为延迟窗(lag window)。自相关加窗等价于对功率谱进行滤波(卷积操作),可实现功率谱的平滑(降方差),同时缓解谱泄露引入的偏置,但相应牺牲了频率分辨率。这其中相较窗口形状,更重要的是窗口长度,M = N / K \small M=N/K M = N / K K K K
对周期图方差的理解 X k = ∑ x n e − i 2 π k N n = ∑ x n cos 2 π k n N − i ∑ x n sin 2 π k n N X_k = \sum x_n e^{-i\frac{2\pi k}{N} n} = \sum x_n \cos\frac{2\pi k n}{N} - i\sum x_n \sin\frac{2\pi k n}{N} X k = ∑ x n e − i N 2 π k n = ∑ x n cos N 2 π k n − i ∑ x n sin N 2 π k n x n x_n x n x n x_n x n X k X_k X k ∣ X k ∣ 2 |X_k|^2 ∣ X k ∣ 2 σ 2 \sigma^2 σ 2
∣ 1 N ∑ x n σ ∣ 2 ∼ χ 1 2 , ∣ 2 N ∑ x n cos 2 π k n N σ ∣ 2 ∼ χ 1 2 , 2 N σ 2 ∣ X k ∣ 2 ∼ χ 2 2 \left|\frac{1}{\sqrt{N}}\sum \frac{x_n}{\sigma}\right|^2 \sim \chi^2_1, ~~ \left|\sqrt{\frac{2}{N}}\sum \frac{x_n \cos\frac{2\pi k n}{N}}{\sigma}\right|^2 \sim \chi^2_1, ~~ \frac{2}{N\sigma^2}|X_k|^2 \sim \chi^2_2
∣ ∣ ∣ ∣ ∣ N 1 ∑ σ x n ∣ ∣ ∣ ∣ ∣ 2 ∼ χ 1 2 , ∣ ∣ ∣ ∣ ∣ ∣ N 2 ∑ σ x n cos N 2 π k n ∣ ∣ ∣ ∣ ∣ ∣ 2 ∼ χ 1 2 , N σ 2 2 ∣ X k ∣ 2 ∼ χ 2 2
由此,离散谱估计∣ X k N ∣ 2 ∼ σ 2 2 N χ 2 2 \left|\frac{X_k}{N}\right|^2 \sim \frac{\sigma^2}{2N}\chi^2_2 ∣ ∣ ∣ N X k ∣ ∣ ∣ 2 ∼ 2 N σ 2 χ 2 2 σ 2 N \frac{\sigma^2}{N} N σ 2 ( σ 2 N ) 2 \left(\frac{\sigma^2}{N}\right)^2 ( N σ 2 ) 2 1 N f s ∣ X k ∣ 2 ∼ σ 2 2 f s χ 2 2 \frac{1}{Nf_s}|X_k|^2 \sim \frac{\sigma^2}{2f_s}\chi^2_2 N f s 1 ∣ X k ∣ 2 ∼ 2 f s σ 2 χ 2 2 σ 2 f s \frac{\sigma^2}{f_s} f s σ 2 ( σ 2 f s ) 2 \left(\frac{\sigma^2}{f_s}\right)^2 ( f s σ 2 ) 2 信号能量被分配到了各频段 ,总功率守恒(Parseval定理);而从方差(随机性)角度理解,随机性也被分配到各频段 ,经过取平方,最终功率谱估计的标准差与功率谱本身相当。从x n x_n x n X k X_k X k
对于一般的高斯噪声,可理解为由白噪声经过成形滤波得到,∣ X k ∣ 2 = ∣ X k ′ ∣ 2 S ( f ) |X_k|^2=|X'_k|^2S(f) ∣ X k ∣ 2 = ∣ X k ′ ∣ 2 S ( f ) ∼ 1 2 S ( f ) χ 2 2 \sim \frac{1}{2}S(f)\chi^2_2 ∼ 2 1 S ( f ) χ 2 2 S ( f ) S(f) S ( f ) S 2 ( f ) S^2(f) S 2 ( f ) 渐近 无偏,但不是一致的,方差为频谱自身的平方。这一结论不依赖于样本数(采样数)N N N K K K 1 K \frac{1}{\sqrt{K}} K 1
注意,除白噪声外,周期图估计是渐进无偏,也即有偏的,利用与自相关法的等价性:
E { S N ( P ) [ k ] } = S ( f ) ∗ 1 f s F N ( 2 π f f s ) E\{ \mathbf{S}_N^{(P)}[k] \} = S(f) * \frac{1}{f_s} F_N\left(\frac{2\pi f}{f_s}\right)
E { S N ( P ) [ k ] } = S ( f ) ∗ f s 1 F N ( f s 2 π f )
频谱的动态范围越大,偏置越大。加窗可以减少频谱泄露,降低偏置,但会相应增加谱估计的方差(压低边缘信号,引入了额外波动),分段求平均则可降低方差。
随机过程运算
分析随机过程功率谱时通常先减去均值,只考虑零均值过程。对于均值非零的广义平稳过程,可理解为零均值过程加上常数,后者会在自相关中贡献常数项,并在功率谱中对应位于零点的δ \delta δ x ( t ) \mathbf{x}(t) x ( t )
随机信号相加:y ( t ) = x 1 ( t ) + x 2 ( t ) \mathbf{y}(t) = \mathbf{x}_1(t) + \mathbf{x}_2(t) y ( t ) = x 1 ( t ) + x 2 ( t )
r y y ( τ ) = r x 1 x 1 ( τ ) + r x 2 x 2 ( τ ) + r x 1 x 2 ( τ ) + r x 2 x 1 ( τ ) r_\mathbf{yy}(\tau) = r_\mathbf{x_1x_1}(\tau) + r_\mathbf{x_2x_2}(\tau) + r_\mathbf{x_1x_2}(\tau) + r_\mathbf{x_2x_1}(\tau)
r y y ( τ ) = r x 1 x 1 ( τ ) + r x 2 x 2 ( τ ) + r x 1 x 2 ( τ ) + r x 2 x 1 ( τ )
若两个随机过程x 1 ( t ) , x 2 ( t ) \mathbf{x}_1(t), \mathbf{x}_2(t) x 1 ( t ) , x 2 ( t ) r y y ( τ ) = r x 1 x 1 ( τ ) + r x 2 x 2 ( τ ) r_\mathbf{yy}(\tau) = r_\mathbf{x_1x_1}(\tau) + r_\mathbf{x_2x_2}(\tau) r y y ( τ ) = r x 1 x 1 ( τ ) + r x 2 x 2 ( τ ) S y y ( f ) = S x 1 x 1 ( f ) + S x 2 x 2 ( f ) S_\mathbf{yy}(f) = S_\mathbf{x_1x_1}(f) + S_\mathbf{x_2x_2}(f) S y y ( f ) = S x 1 x 1 ( f ) + S x 2 x 2 ( f )
随机信号与确定信号相加:y ( t ) = x ( t ) + s ( t ) \mathbf{y}(t) = \mathbf{x}(t) + s(t) y ( t ) = x ( t ) + s ( t )
r y y ( t , τ ) = r x x ( τ ) + s ( t ) ‾ μ x + s ( t + τ ) μ x ‾ + s ( t ) ‾ s ( t + τ ) r_\mathbf{yy}(t, \tau) = r_\mathbf{xx}(\tau) + \overline{s(t)}\mu_\mathbf{x} + s(t+\tau)\overline{\mu_\mathbf{x}} + \overline{s(t)}s(t+\tau)
r y y ( t , τ ) = r x x ( τ ) + s ( t ) μ x + s ( t + τ ) μ x + s ( t ) s ( t + τ )
考虑到x ( t ) \mathbf{x}(t) x ( t ) r y y ( t , τ ) = r x x ( τ ) + s ( t ) ‾ s ( t + τ ) r_\mathbf{yy}(t, \tau) = r_\mathbf{xx}(\tau) + \overline{s(t)}s(t+\tau) r y y ( t , τ ) = r x x ( τ ) + s ( t ) s ( t + τ ) y ( t ) \mathbf{y}(t) y ( t ) t t t s ( t ) = e i ω s t , s ( t ) ‾ s ( t + τ ) = e i ω s τ s(t) = e^{i\omega_s t}, ~ \overline{s(t)}s(t+\tau)=e^{i\omega_s \tau} s ( t ) = e i ω s t , s ( t ) s ( t + τ ) = e i ω s τ x ( t ) \mathbf{x}(t) x ( t ) 1 2 π ω s \frac{1}{2\pi}\omega_s 2 π 1 ω s δ \delta δ s ( t ) s(t) s ( t ) y ( t ) \mathbf{y}(t) y ( t ) x ( t ) \mathbf{x}(t) x ( t ) δ \delta δ
随机信号与确定信号相乘:y ( t ) = x ( t ) s ( t ) \mathbf{y}(t) = \mathbf{x}(t) s(t) y ( t ) = x ( t ) s ( t )
r y y ( t , τ ) = s ( t ) ‾ s ( t + τ ) r x x ( τ ) r_\mathbf{yy}(t, \tau) = \overline{s(t)}s(t+\tau)r_\mathbf{xx}(\tau)
r y y ( t , τ ) = s ( t ) s ( t + τ ) r x x ( τ )
一般情况,y ( t ) \mathbf{y}(t) y ( t ) t t t s ( t ) = e i ω s t , s ( t ) ‾ s ( t + τ ) = e i ω s τ s(t) = e^{i\omega_s t}, ~ \overline{s(t)}s(t+\tau)=e^{i\omega_s \tau} s ( t ) = e i ω s t , s ( t ) s ( t + τ ) = e i ω s τ y ( t ) \mathbf{y}(t) y ( t ) S y y ( f ) = S x x ( f − 1 2 π ω s ) S_\mathbf{yy}(f) = S_\mathbf{xx}(f-\frac{1}{2\pi}\omega_s) S y y ( f ) = S x x ( f − 2 π 1 ω s ) 1 2 π ω s \frac{1}{2\pi}\omega_s 2 π 1 ω s s ( t ) = cos ω s t s(t) = \cos\omega_s t s ( t ) = cos ω s t S y y ( f ) = 1 4 [ S x x ( f + 1 2 π ω s ) + S x x ( f − 1 2 π ω s ) ] S_\mathbf{yy}(f) = \frac{1}{4}[S_\mathbf{xx}(f+\frac{1}{2\pi}\omega_s) + S_\mathbf{xx}(f-\frac{1}{2\pi}\omega_s)] S y y ( f ) = 4 1 [ S x x ( f + 2 π 1 ω s ) + S x x ( f − 2 π 1 ω s ) ]
随机信号滤波:y ( t ) = x ( t ) ∗ h ( t ) \mathbf{y}(t) = \mathbf{x}(t) * h(t) y ( t ) = x ( t ) ∗ h ( t )
E { y ( t ) } = E { x ( t ) } H ( 0 ) E\{\mathbf{y}(t)\} = E\{\mathbf{x}(t)\}H(0)
E { y ( t ) } = E { x ( t ) } H ( 0 )
其中H ( 0 ) H(0) H ( 0 ) h ( t ) h(t) h ( t ) x ( t ) \mathbf{x}(t) x ( t ) y ( t ) \mathbf{y}(t) y ( t ) h ( t ) h(t) h ( t ) H ( f ) H(f) H ( f ) H ( 0 ) H(0) H ( 0 )
r y x ( τ ) = r x x ( τ ) ∗ h ( τ ) , r x y ( τ ) = r y x ( − τ ) = r x x ( τ ) ∗ h ( − τ ) r_\mathbf{yx}(\tau) = r_\mathbf{xx}(\tau) * h(\tau), ~~~ r_\mathbf{xy}(\tau) = r_\mathbf{yx}(-\tau) = r_\mathbf{xx}(\tau) * h(-\tau)
r y x ( τ ) = r x x ( τ ) ∗ h ( τ ) , r x y ( τ ) = r y x ( − τ ) = r x x ( τ ) ∗ h ( − τ )
r y y ( τ ) = r x y ( τ ) ∗ h ( τ ) = r x x ( τ ) ∗ h ( − τ ) ∗ h ( τ ) r_\mathbf{yy}(\tau) = r_\mathbf{xy}(\tau) * h(\tau) = r_\mathbf{xx}(\tau) * h(-\tau) * h(\tau)
r y y ( τ ) = r x y ( τ ) ∗ h ( τ ) = r x x ( τ ) ∗ h ( − τ ) ∗ h ( τ )
S y y ( f ) = S x x ( f ) ∣ H ( f ) ∣ 2 S_\mathbf{yy}(f) = S_\mathbf{xx}(f) |H(f)|^2
S y y ( f ) = S x x ( f ) ∣ H ( f ) ∣ 2
噪声与信噪比
类似于包含各波长的可见光为白光,各频率功率均等的随机信号被称为白噪声,对应功率谱密度为常数。所有频谱不为常数的随机噪声都被称为有色噪声:类比可见光,当低频成分占比多时,颜色偏红,功率谱∝ f − 1 ∝f^{-1} ∝ f − 1 ∝ f − 2 ∝f^{-2} ∝ f − 2 ∝ f ∝f ∝ f ∝ f 2 ∝f^2 ∝ f 2
不过很多时候,颜色的区分并不严格,红噪声可能指代任何低频功率更高或功率谱呈负指数分布的噪声,相反高频成分偏多的噪声被统称为蓝噪声。负指数谱(红),低频成分占比多,系统自相关性持续较长,具有长时记忆;正指数谱(蓝),高频成分占比多,系统具有反持久性,相邻增量间反相关,前者在信号处理中很常见。
白噪声 :S ( f ) ∝ 1 S(f)\propto 1 S ( f ) ∝ 1
热噪声:电子设备中无源器件,由于大量电子热运动引起的噪声
散粒噪声:电子设备中有源器件,由于电子发射不均匀性(涨落)所引起的噪声
白噪声功率谱密度为常数,通常记为N 0 N_0 N 0 N 0 / 2 N_0/2 N 0 / 2 N 0 N_0 N 0 r x x ( τ ) = N 0 2 δ ( τ ) r_\mathbf{xx}(\tau) = \frac{N_0}{2}\delta(\tau) r x x ( τ ) = 2 N 0 δ ( τ ) E { x ( t 1 ) x ( t 2 ) } E\{\mathbf{x}(t_1)\mathbf{x}(t_2)\} E { x ( t 1 ) x ( t 2 ) } E { x 2 ( t ) } E\{\mathbf{x}^2(t)\} E { x 2 ( t ) } σ 2 = E { x 2 ( t ) } = r x x ( 0 ) = ∫ S ( f ) d f = P \sigma^2 = E\{\mathbf{x}^2(t)\} = r_\mathbf{xx}(0) = \int S(f)df = P σ 2 = E { x 2 ( t ) } = r x x ( 0 ) = ∫ S ( f ) d f = P
现实中白噪声一般有较广但有限的带宽,通常会先对信号进行低通或带通滤波,之后再以超过Nyquist速率的采样率进行采样。此时:
σ 2 = E { x 2 ( t ) } = r x x ( 0 ) = ∫ N 0 2 ∣ H ( f ) ∣ 2 d f = N 0 B \sigma^2 = E\{\mathbf{x}^2(t)\} = r_\mathbf{xx}(0) = \int \frac{N_0}{2}|H(f)|^2df = N_0 B
σ 2 = E { x 2 ( t ) } = r x x ( 0 ) = ∫ 2 N 0 ∣ H ( f ) ∣ 2 d f = N 0 B
H ( f ) H(f) H ( f ) B B B ∣ H ( f ) ∣ 2 = 2 B r e c t ( f 2 B ) |H(f)|^2=2B{\rm rect}(\frac{f}{2B}) ∣ H ( f ) ∣ 2 = 2 B r e c t ( 2 B f ) δ \delta δ s i n c {\rm sinc} s i n c r x x ( τ ) = N 0 B s i n c ( 2 B τ ) r_\mathbf{xx}(\tau) = N_0B{\rm sinc}(2B\tau) r x x ( τ ) = N 0 B s i n c ( 2 B τ ) r x x [ k ] = N 0 B δ [ k ] r_\mathbf{xx}[k] =N_0B \delta[k] r x x [ k ] = N 0 B δ [ k ] δ [ k ] \delta[k] δ [ k ] 克氏符 ,而非狄拉克δ \delta δ τ = 0 \tau=0 τ = 0
注意区分功率σ 2 \sigma^2 σ 2 N 0 N_0 N 0 S ( f ) = σ 2 S(f)=\sigma^2 S ( f ) = σ 2 f / f s f/f_s f / f s [ − 1 2 , 1 2 ) [-\frac{1}{2}, \frac{1}{2}) [ − 2 1 , 2 1 ) N 0 = σ 2 N_0=\sigma^2 N 0 = σ 2
粉噪声 :S ( f ) ∝ 1 / f S(f)\propto 1/f S ( f ) ∝ 1 / f 1/f噪声 、闪烁噪声∝ 1 / f ∝1/f ∝ 1 / f
红噪声:S ( f ) ∝ 1 / f 2 S(f)\propto 1/f^2 S ( f ) ∝ 1 / f 2 ∝ 1 / f 2 ∝1/f^2 ∝ 1 / f 2
噪声模拟
对于白噪声,最常用的形式是(均值为零的)独立同分布(i.d.d.)过程,具体分布并没有要求。当共同分布为零均值正态分布时,又被称为高斯白噪声 。注意,单独的高斯噪声,仅要求随机信号服从高斯分布,但并不要相互独立,也就不一定是白噪声。
模拟高斯白噪声,可直接按x n ∼ N ( 0 , σ 2 ) x_n \sim \mathcal{N}(0, \sigma^2) x n ∼ N ( 0 , σ 2 ) σ 2 \sigma^2 σ 2 [ − f s 2 , f s 2 ) [-\frac{f_s}{2}, \frac{f_s}{2}) [ − 2 f s , 2 f s ) σ 2 / f s \sigma^2/f_s σ 2 / f s σ 2 / N \sigma^2/N σ 2 / N r x x [ k ] = σ 2 δ [ k ] r_\mathbf{xx}[k] = \sigma^2\delta[k] r x x [ k ] = σ 2 δ [ k ] δ [ k ] \delta[k] δ [ k ] δ \delta δ σ 2 \sigma^2 σ 2 E { ∣ X k ∣ 2 N } = σ 2 E\left\{\frac{|X_k|^2}{N}\right\} = \sigma^2 E { N ∣ X k ∣ 2 } = σ 2
实际信号通常是功率谱∣ X k N ∣ 2 \left|\frac{X_k}{N}\right|^2 ∣ ∣ ∣ N X k ∣ ∣ ∣ 2 ∣ X k ∣ 2 N f s \frac{|X_k|^2}{N f_s} N f s ∣ X k ∣ 2 f s f_s f s f s f_s f s
对于一般的噪声功率谱密度(PSD)S n ( f ) S_n(f) S n ( f )
根据功率谱的周期图估计S ( f ) = 1 T ∣ X ( f ) ∣ 2 = 1 N f s ∣ X k ∣ 2 S(f) = \frac{1}{T}|X(f)|^2 = \frac{1}{Nf_s}|X_k|^2 S ( f ) = T 1 ∣ X ( f ) ∣ 2 = N f s 1 ∣ X k ∣ 2 ∣ X k ∣ = N f s S ( f ) |X_k| = \sqrt{N f_s S(f)} ∣ X k ∣ = N f s S ( f ) [ 0 , 2 π ) [0, 2\pi) [ 0 , 2 π ) X k = N f s S ( f ) e i ϕ k X_k = \sqrt{N f_s S(f)} e^{i\phi_k} X k = N f s S ( f ) e i ϕ k
E { X ( f 1 ) ‾ X ( f ) } = E { ∫ x ( t 1 ) e i 2 π f 1 t 1 d t 1 ∫ x ( t ) e − i 2 π f t d t } = ∫ E { x ( t 1 ) x ( t 1 + τ ) } e i 2 π f 1 t 1 e − i 2 π f ( t 1 + τ ) d t 1 d τ = ∫ r x x ( τ ) e − i 2 π f τ d τ ∫ e i 2 π ( f 1 − f ) t 1 d t 1 = S ( f ) δ ( f 1 − f ) \begin{aligned}
E\left\{\overline{\mathbf{X}(f_1)}\mathbf{X}(f)\right\} &= E\left\{ \int \mathbf{x}(t_1)e^{i 2\pi f_1 t_1}dt_1 \int \mathbf{x}(t)e^{-i 2\pi f t}dt \right\}\\
& = \int E\left\{ \mathbf{x}(t_1) \mathbf{x}(t_1+\tau)\right\} e^{i 2\pi f_1 t_1}e^{-i 2\pi f (t_1+\tau)} dt_1d\tau \\
& = \int r_\mathbf{xx}(\tau) e^{-i 2\pi f \tau} d\tau \int e^{i 2\pi (f_1-f) t_1} dt_1 \\
& = S(f)\delta(f_1-f)
\end{aligned} E { X ( f 1 ) X ( f ) } = E { ∫ x ( t 1 ) e i 2 π f 1 t 1 d t 1 ∫ x ( t ) e − i 2 π f t d t } = ∫ E { x ( t 1 ) x ( t 1 + τ ) } e i 2 π f 1 t 1 e − i 2 π f ( t 1 + τ ) d t 1 d τ = ∫ r x x ( τ ) e − i 2 π f τ d τ ∫ e i 2 π ( f 1 − f ) t 1 d t 1 = S ( f ) δ ( f 1 − f )
这里利用了自相关函数的稳定性(不依赖t 1 t_1 t 1 X k X_k X k
X k = { f s N 1 2 S + ( f k ) e i ϕ k if 0 < k < N 2 f s N S + ( f k ) if k = 0 , N 2 X_k=\begin{cases} \sqrt{f_s N \frac{1}{2}S_{\tiny +}(f_k)} e^{i\phi_k} &\text{if} ~~ 0<k<\frac{N}{2}\\ \sqrt{f_s N S_{\tiny +}(f_k)} &\text{if} ~~ k=0, ~ \frac{N}{2}\end{cases}
X k = { f s N 2 1 S + ( f k ) e i ϕ k f s N S + ( f k ) if 0 < k < 2 N if k = 0 , 2 N
注意这里只考虑正频率,S + ( f k ) S_{\tiny +}(f_k) S + ( f k ) S + ( 0 ) = 0 S_{\tiny +}(0) = 0 S + ( 0 ) = 0 X 0 = 0 X_0=0 X 0 = 0 S ( f k ) = N 0 S(f_k)= N_0 S ( f k ) = N 0 σ 2 = N 0 2 f s \sigma^2=\frac{N_0}{2}f_s σ 2 = 2 N 0 f s
这里有个问题:随机的只有相位,幅值是确定的,而根据前面对周期图法的分析,幅值是服从χ 2 2 \chi^2_2 χ 2 2 Timmer & Koenig 1995 据此认为更合理的噪声生成方式是:
X k = { [ N ( 0 , 1 ) + i N ( 0 , 1 ) ] 1 2 N f s S + ( f k ) if 0 < k < N 2 N ( 0 , 1 ) N f s S + ( f k ) if k = 0 , N 2 X_k=\begin{cases} [\mathcal{N}(0, 1) + i\mathcal{N}(0, 1)]\frac{1}{2} \sqrt{N f_s S_{\tiny +}(f_k)} &\text{if} ~~ 0<k<\frac{N}{2}\\ \mathcal{N}(0, 1) \sqrt{N f_s S_{\tiny +}(f_k)} &\text{if} ~~ k=0, ~ \frac{N}{2}\end{cases}
X k = { [ N ( 0 , 1 ) + i N ( 0 , 1 ) ] 2 1 N f s S + ( f k ) N ( 0 , 1 ) N f s S + ( f k ) if 0 < k < 2 N if k = 0 , 2 N
这里复频谱的实部与虚部作为完全独立的随机变量,与前面频谱相位随机分布相对应,所不同的是幅值也具有了随机性。注意S + ( f k ) S_{\tiny +}(f_k) S + ( f k ) X k X_k X k astroML 中彩色噪声模拟就用了该算法。
还有一种思路是先在时域生成高斯白噪声,DFT得到对应复谱,再使用成形滤波S ( f ) \sqrt{S(f)} S ( f )
x n ( w ) ∼ N ( 0 , 1 ) , X k = X k ( w ) f s S ( f ) x^{(w)}_n \sim \mathcal{N}(0, 1), ~~~ X_k = X^{(w)}_k\sqrt{f_s S(f)}
x n ( w ) ∼ N ( 0 , 1 ) , X k = X k ( w ) f s S ( f )
其中红噪声和紫噪声可通过对白噪声信号简单积分(自回归AR)和差分(移动平均MA)得到。
最后,Matlab 中使用了更为复杂的实现方式:负指数谱用的是自回归AR模型,除了粉红和红噪声使用双二次IIR滤波器(sosfilt);正指数谱则是移动平均MA模型,除了紫噪声使用一阶滤波器,不清楚这样选择的优势。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 import numpy as npfrom scipy import signalfrom matplotlib import pyplot as pltdef generate_noise (N, fs, color, noise_generater, seed=None ): noise_power_index = {'white' : 0 , 'pink' : -1 , 'red' : -2 } def power_law_spectra (alpha ): return lambda f: np.power(f, alpha, where=(f!=0 )) slope = noise_power_index[color] psd_func = power_law_spectra(slope) L = N//2 + 1 freqs = np.arange(L)*fs/N psd_scaled = psd_func(freqs) * fs noises = noise_generater(N, psd_scaled, seed) return noises, psd_scaled def psd_compare (noise_generater, random_seed=42 ): T, fs = 10 , 4096 N = int (T*fs) for color in ['white' , 'pink' , 'red' ]: noises, psd_scaled = generate_noise(N, fs, color, noise_generater, random_seed) freqs, psd = signal.periodogram(noises, fs=fs) if color == 'white' : color = 'grey' plt.loglog(freqs, psd, color=color) plt.loglog(freqs, psd_scaled/fs) plt.ylim(1e-12 , 1e3 ) plt.show() def show_noise (noise_generater, random_seed=42 ): T, fs = 10 , 4096 N = int (T*fs) times = np.arange(N)/fs for color in ['white' , 'pink' , 'red' ]: noises, psd_scaled = generate_noise(N, fs, color, noise_generater, random_seed) sigma = np.sqrt(np.sum (psd_scaled)/N) if color == 'white' : color = 'grey' plt.plot(times, noises/sigma, color=color) plt.show() def noise_from_psd1 (N, psd, seed ): L = N//2 + 1 A_k = np.sqrt(psd/2 * N) rng = np.random.default_rng(seed) phases = rng.uniform(0. , 2 *np.pi, size=L) X_k = A_k*np.exp(1j *phases) X_k[0 ] = A_k[0 ]*np.sqrt(2 ) if N % 2 == 0 : X_k[-1 ] = A_k[-1 ]*np.sqrt(2 ) noises = np.fft.irfft(X_k) return noises def noise_from_psd2 (N, psd, seed ): L = N//2 + 1 rng = np.random.default_rng(seed) X1 = rng.normal(0. , 1. , size=L) X2 = rng.normal(0. , 1. , size=L) X_k = (X1 + 1j *X2)/2 * np.sqrt(psd * N) X_k[0 ] = 2 *X_k[0 ].real if N % 2 ==0 : X_k[-1 ] = 2 *X_k[-1 ].real noises = np.fft.irfft(X_k) return noises def noise_from_psd3 (N, psd, seed ): rng = np.random.default_rng(seed) X_white = np.fft.rfft(rng.normal(0 , 1 , N)) X_k = X_white * np.sqrt(psd) noises = np.fft.irfft(X_k) return noises psd_compare(noise_from_psd1) psd_compare(noise_from_psd2) psd_compare(noise_from_psd3) show_noise(noise_from_psd3) def psd_mean (noise_generater, random_seed=None ): T, fs = 10 , 4096 N = int (T*fs) color = 'white' for _ in range (10 ): noises, psd_scaled = generate_noise(N, fs, color, noise_generater, random_seed) freqs, psd = signal.periodogram(noises, fs=fs) if color == 'white' : color = 'grey' plt.loglog(freqs, psd, color=color) plt.loglog(freqs, psd_scaled/fs) plt.ylim(1e-12 , 1e3 ) plt.show()
SNR is the ratio of detected signal to uncertainty of the signal measurement. Higher is better.
系统灵敏度是对于给定的SNR和观测时长,系统所能分辨的流量水平下限。λ \lambda λ
SNR提升
常见噪声
信号自身(散粒噪声):光子到达时间随机性造成的流量波动
读出噪声(量化噪声):信号读出过程(模拟变数字)引入的噪声
暗电流噪声(热噪声):
提升SNR
堆栈(stacking):增加积分时长
滤光片(filter):窄带滤波
平稳信号提升信噪比
https://jonrista.com/the-astrophotographers-guide/astrophotography-basics/snr/
在单次观测中读出噪声是固定的,不随积分时间变化,但却会随着堆栈次数增加,因此在不过曝的前提下优先增加积分时间,之后再进行堆栈。
匹配滤波技术
假设噪声是与信号不相关的加性噪声有:
x ( t ) = s ( t − t 0 ) + n ( t ) , y ( t ) = h ( t ) ∗ x ( t ) \mathbf{x}(t) = s(t-t_0) + \mathbf{n}(t), ~~~ \mathbf{y}(t) = h(t)*\mathbf{x}(t)
x ( t ) = s ( t − t 0 ) + n ( t ) , y ( t ) = h ( t ) ∗ x ( t )
匹配滤波
这里先从“相关”视角建立对匹配滤波的直观理解。在数据噪声为白噪声时,匹配滤波就是信号模板s ( t ) s(t) s ( t ) x ( t ) \mathbf{x}(t) x ( t )
y ( t ) = ( s ⋆ x ) ( t ) = ∫ s ( τ − t ) x ( τ ) d τ , Y ( f ) = X s ( f ) ‾ X ( f ) \mathbf{y}(t) = (s\star \mathbf{x})(t) = \int s(\tau-t) \mathbf{x}(\tau) d\tau, ~~~~ Y(f) = \overline{X_s(f)}X(f)
y ( t ) = ( s ⋆ x ) ( t ) = ∫ s ( τ − t ) x ( τ ) d τ , Y ( f ) = X s ( f ) X ( f )
频域形式可由傅里叶变换的相关定理或卷积定理得到:s ( t ) s(t) s ( t ) s ( − t ) s(-t) s ( − t ) X s ( f ) ‾ \overline{X_s(f)} X s ( f ) y ( t ) = r s s ( t − t 0 ) + r s n ( t ) \mathbf{y}(t) = r_{ss}(t-t_0) + r_{s\mathbf{n}}(t) y ( t ) = r s s ( t − t 0 ) + r s n ( t ) E { r s n ( t ) } = 0 , E { y ( t ) } = r s s ( t − t 0 ) E\{r_{s\mathbf{n}}(t)\}=0, E\{\mathbf{y}(t)\}= r_{ss}(t-t_0) E { r s n ( t ) } = 0 , E { y ( t ) } = r s s ( t − t 0 ) t t t t = t 0 t=t_0 t = t 0
对于非白噪声情况,匹配滤波是将信号模板与数据分别用噪声功率谱S n ( f ) S_n(f) S n ( f )
Y ( f ) = X s ( f ) ‾ S n X ( f ) S n ( f ) = X s ( f ) ‾ X ( f ) S n ( f ) Y(f) = \frac{\overline{X_s(f)}}{\sqrt{S_n}}\frac{X(f)}{\sqrt{S_n(f)}} = \frac{\overline{X_s(f)}X(f)}{S_n(f)}
Y ( f ) = S n X s ( f ) S n ( f ) X ( f ) = S n ( f ) X s ( f ) X ( f )
相比白噪声时的X s ( f ) ‾ X ( f ) \overline{X_s(f)}X(f) X s ( f ) X ( f )
y ( t ) = F − 1 { X s ( f ) S n ( f ) } ⋆ F − 1 { X ( f ) S n ( f ) } = F − 1 { X s ( f ) S n ( f ) } ⋆ x ( t ) \mathbf{y}(t) = \mathcal{F}^{-1}\left\{\frac{X_s(f)}{\sqrt{S_n(f)}}\right\} \star \mathcal{F}^{-1}\left\{\frac{X(f)}{\sqrt{S_n(f)}}\right\}=\mathcal{F}^{-1}\left\{\frac{X_s(f)}{S_n(f)}\right\} \star \mathbf{x}(t)
y ( t ) = F − 1 { S n ( f ) X s ( f ) } ⋆ F − 1 { S n ( f ) X ( f ) } = F − 1 { S n ( f ) X s ( f ) } ⋆ x ( t )
最终y ( t ) = r s ′ s ′ ( t − t 0 ) + r s ′ n ( t ) , s ′ ( t ) = F − 1 { X s ( f ) S n ( f ) } \mathbf{y}(t) = r_{s's'}(t-t_0) + r_{s'\mathbf{n}}(t), s'(t) = \mathcal{F}^{-1}\left\{\frac{X_s(f)}{S_n(f)}\right\} y ( t ) = r s ′ s ′ ( t − t 0 ) + r s ′ n ( t ) , s ′ ( t ) = F − 1 { S n ( f ) X s ( f ) } y ( t ) \mathbf{y}(t) y ( t ) t t t t 0 t_0 t 0 y ( t ) \mathbf{y}(t) y ( t ) ∣ y ( t ) ∣ |\mathbf{y}(t)| ∣ y ( t ) ∣
实际中s ( t ) s(t) s ( t ) s ( t ) s(t) s ( t ) k s ( t ) k~s(t) k s ( t ) k k k X t → X t / E , E = ∫ ∣ X t ( f ) ∣ 2 d f X_{\frak t} \rightarrow X_{\frak t} /\sqrt{E}, E = \int \left| X_{\frak t}(f) \right|^2 df X t → X t / E , E = ∫ ∣ X t ( f ) ∣ 2 d f E = ∫ ∣ X t ( f ) ‾ S n ( f ) ∣ 2 d f E ={\displaystyle \int} \left| \frac{\overline{X_{\frak t}(f)}}{\sqrt{S_n(f)}} \right|^2 df E = ∫ ∣ ∣ ∣ ∣ ∣ S n ( f ) X t ( f ) ∣ ∣ ∣ ∣ ∣ 2 d f
y ^ ( t ) = F − 1 { X t ( f ) ‾ X ( f ) S n ( f ) } / ∫ ∣ X t ( f ) ∣ 2 S n ( f ) d f \hat{\mathbf{y}}(t) = \mathcal{F}^{-1}\left\{\frac{\overline{X_{\frak t}(f)}X(f)}{S_n(f)}\right\} / \sqrt{\int \frac{ \left|X_{\frak t} (f) \right|^2}{S_n(f)} df}
y ^ ( t ) = F − 1 { S n ( f ) X t ( f ) X ( f ) } / ∫ S n ( f ) ∣ X t ( f ) ∣ 2 d f
归一化后,y ^ ( t ) \hat{\mathbf{y}}(t) y ^ ( t ) y ^ ( t ) \hat{\mathbf{y}}(t) y ^ ( t ) y ^ n ( t ) \hat{\mathbf{y}}_\mathbf{n}(t) y ^ n ( t ) ∣ X t ( f ) ‾ S n ( f ) ∣ 2 S n ( f ) / ∫ ∣ X t ( f ) ∣ 2 S n ( f ) d f \left|\frac{\overline{X_{\frak t}(f)}}{S_n(f)}\right|^2 S_n(f) / \int \frac{ \left|X_{\frak t} (f) \right|^2}{S_n(f)} df ∣ ∣ ∣ ∣ S n ( f ) X t ( f ) ∣ ∣ ∣ ∣ 2 S n ( f ) / ∫ S n ( f ) ∣ X t ( f ) ∣ 2 d f E { y ^ n 2 ( t ) } = 1 E\{\hat{\mathbf{y}}^2_\mathbf{n}(t)\}=1 E { y ^ n 2 ( t ) } = 1
S N R ( t ) = P y s ( t ) P y n ( t ) = E { y ^ ( t ) } 2 E { y ^ n 2 ( t ) } = E { y ^ ( t ) } 2 = y ^ s 2 ( t ) \mathrm{SNR}(t) = \frac{P_{y_s}(t)}{P_\mathbf{y_n}(t)} = \frac{E\{\hat{\mathbf{y}}(t)\}^2}{E\{\hat{\mathbf{y}}^2_\mathbf{n}(t)\}} = E\{\hat{\mathbf{y}}(t)\}^2 = \hat{y}^2_s(t)
S N R ( t ) = P y n ( t ) P y s ( t ) = E { y ^ n 2 ( t ) } E { y ^ ( t ) } 2 = E { y ^ ( t ) } 2 = y ^ s 2 ( t )
这就是用白化后模板能量进行归一化的好处。最后,可以证明,当模板与信号相匹配时信噪比最大:
S N R ( t ) = y ^ s 2 ( t ) = ∣ ∫ X t ( f ) ‾ X s ( f ) e − i 2 π f t 0 S n ( f ) e i 2 π f t d f ∫ ∣ X t ( f ) ∣ 2 S n ( f ) d f ∣ 2 ≤ ∫ ∣ X s ( f ) ∣ 2 S n ( f ) d f \mathrm{SNR}(t) = \hat{y}^2_s(t) = \left|\frac{ \int \frac{\overline{X_{\frak t}(f)}X_s(f)e^{-i2\pi f t_0}}{S_n(f)}e^{i2\pi f t} df }{ \sqrt{\int \frac{ \left|X_{\frak t} (f) \right|^2}{S_n(f)} df} }\right|^2 \le \int \frac{ \left|X_s (f) \right|^2}{S_n(f)} df
S N R ( t ) = y ^ s 2 ( t ) = ∣ ∣ ∣ ∣ ∣ ∣ ∣ ∫ S n ( f ) ∣ X t ( f ) ∣ 2 d f ∫ S n ( f ) X t ( f ) X s ( f ) e − i 2 π f t 0 e i 2 π f t d f ∣ ∣ ∣ ∣ ∣ ∣ ∣ 2 ≤ ∫ S n ( f ) ∣ X s ( f ) ∣ 2 d f
上面利用了柯西-施瓦兹不等式∣ ∫ f ( x ) g ( x ) d x ∣ 2 ≤ ∫ ∣ f ( x ) ∣ 2 d x ∫ ∣ g ( x ) ∣ 2 d x \left|\int f(x) g(x) dx\right|^2 \le \int |f(x)|^2 dx \int |g(x)|^2 dx ∣ ∣ ∣ ∫ f ( x ) g ( x ) d x ∣ ∣ ∣ 2 ≤ ∫ ∣ f ( x ) ∣ 2 d x ∫ ∣ g ( x ) ∣ 2 d x f ( x ) = k g ( x ) ‾ f(x)=k\overline{g(x)} f ( x ) = k g ( x ) X t ( f ) = k X s ( f ) , t = t 0 X_{\frak t}(f)=k X_s(f), t=t_0 X t ( f ) = k X s ( f ) , t = t 0 k s ( t ) ks(t) k s ( t ) t 0 t_0 t 0
最后,从通常的“滤波”角度理解,结论是一致的:
y ( t ) = y s ( t ) + y n ( t ) = s ( t − t 0 ) ∗ h ( t ) + n ( t ) ∗ h ( t ) \mathbf{y}(t) = y_s(t) + \mathbf{y_n}(t) = s(t-t_0)*h(t) + \mathbf{n}(t)*h(t)
y ( t ) = y s ( t ) + y n ( t ) = s ( t − t 0 ) ∗ h ( t ) + n ( t ) ∗ h ( t )
y s ( t ) = F − 1 { Y s ( f ) } , Y s ( f ) = X s ( f ) e − i 2 π f t 0 H ( f ) y_s(t) = \mathcal{F}^{-1}\left\{Y_s(f)\right\}, ~~ Y_s(f) = X_s(f)e^{-i2\pi ft_0}H(f)
y s ( t ) = F − 1 { Y s ( f ) } , Y s ( f ) = X s ( f ) e − i 2 π f t 0 H ( f )
S N R ( t ) = y s 2 ( t ) E { y n 2 ( t ) } = ∣ ∫ X s ( f ) H ( f ) e i 2 π f ( t − t 0 ) d f ∣ 2 ∫ S n ( f ) ∣ H ( f ) ∣ 2 d f ≤ ∫ ∣ X s ( f ) ∣ 2 S n ( f ) d f \mathrm{SNR}(t) = \frac{y^2_s(t)}{E\left\{ \mathbf{y}^2_n(t)\right\} } = \frac{\displaystyle\left|\int X_s(f)H(f) e^{i2\pi f (t-t_0)} df\right|^2}{\displaystyle\int S_n(f)|H(f)|^2 df} \le \int \frac{|X_s(f)|^2}{S_n(f)} df
S N R ( t ) = E { y n 2 ( t ) } y s 2 ( t ) = ∫ S n ( f ) ∣ H ( f ) ∣ 2 d f ∣ ∣ ∣ ∣ ∣ ∫ X s ( f ) H ( f ) e i 2 π f ( t − t 0 ) d f ∣ ∣ ∣ ∣ ∣ 2 ≤ ∫ S n ( f ) ∣ X s ( f ) ∣ 2 d f
上式同样利用了柯西-施瓦兹不等式,信噪比在t 0 t_0 t 0 H ( f ) = k X s ( f ) ‾ S n ( f ) H(f) = k\frac{\overline{X_s(f)}}{S_n(f)} H ( f ) = k S n ( f ) X s ( f )
信号白化的计算
X ( f ) S n ( f ) \frac{X(f)}{\sqrt{S_n(f)}}
S n ( f ) X ( f )
白化后功率谱密度为1,
为什么看到别人的实现中没有N N N f s f_s f s S n S_n S n N = f s N = f_s N = f s
参数估计
匹配滤波只能实现点估计,且受模板网格精细度限制,要获得参数不确定性,需要基于概率分布,利用Fisher信息矩阵(FIM)、MCMC采样等进行区间估计。
Maggiore 2008 GW 7.4.2The PyCBC search for gravitational waves from CBCs
常见随机过程
Random Processes Some Important Random Processes https://www.stat.auckland.ac.nz/~fewster/325/notes.php
https://www.datasciencecentral.com/profiles/blogs/fee-book-applied-stochastic-processes 需要订阅 Data Science Central才能获取
https://en.wikipedia.org/wiki/Stochastic_process https://www.math.ucdavis.edu/~hunter/m280_09/ch5.pdf
https://dlsun.github.io/probability/random-process.html
高斯过程
高斯过程要求任意阶分布均为正态分布,即任意有限时刻随机变量的联合分布均为正态分布∀ n , f ( x 1 , . . . , x n ; t 1 , . . . , t n ) ∼ N \forall n, f(x_1, ..., x_n; t_1, ..., t_n) \sim \mathcal{N} ∀ n , f ( x 1 , . . . , x n ; t 1 , . . . , t n ) ∼ N μ ( t ) \mu(t) μ ( t ) γ x x ( t , t ′ ) \gamma_\mathbf{xx}(t, t') γ x x ( t , t ′ ) x ( t ) ∼ G P ( μ , γ ) \mathbf{x}(t) \sim \mathcal{GP}(\mu, \gamma) x ( t ) ∼ G P ( μ , γ ) r x x ( t , t ′ ) r_\mathbf{xx}(t, t') r x x ( t , t ′ ) t − t ′ t-t' t − t ′ δ \delta δ
高斯过程很常见,但上述诸多情况下有各自的专用描述。高斯过程本身则通常用于实现非参数化的贝叶斯推断、数据拟合、分类,以及Auto-ML/超参数调优等。
非参数化:不去限制函数具体参数,而直接刻画函数性质
函数分布:先验分布,condition on data,得到后验分布
注意,最终得到的不是具体函数,而是函数的分布(性质)
考虑到高斯过程不仅限于一维时序数据,下面换用相关文献中常用标号:自变量记为x x x x ⃗ \vec{x} x m m m k k k
对比通常的数据拟合的,高斯过程为目标函数本身引入先验(这里取均值为0),而考虑到观测数据后,就可得到目标函数的后验分布。
基于这个先验我们可以对观测数据之外的
f ( x ) ∼ G P ( 0 , k ) y ∼ G P ( 0 , k + I σ y 2 ) \begin{aligned}
f(x)& \sim \mathcal{GP}(0, k)\\
y & \sim \mathcal{GP}(0, k+I\sigma^2_y)
\end{aligned} f ( x ) y ∼ G P ( 0 , k ) ∼ G P ( 0 , k + I σ y 2 )
y = f ( x ) + ϵ σ y ϵ ∼ N ( 0 , 1 ) \begin{aligned}
y &= f(x) + \epsilon \sigma_y\\
\epsilon &\sim \mathcal{N}(0, 1)
\end{aligned} y ϵ = f ( x ) + ϵ σ y ∼ N ( 0 , 1 )
高斯过程 v.s. (贝叶斯)神经网络
Inference in the GP made on a finite subset of the function f f f
协方差函数(核函数)的选取取决于目标函数的性质,如平滑性、周期性、均匀性(高维)等。选定核函数,就确定了随机函数的先验分布 。引入数据限制后,函数分布将被极大限制,实现对数据的自动拟合。最后从 后验分布 中采样,得到函数分布的均值和波动范围(置信区间)。
最常见的核函数是径向基函数RBF,两个超参数振幅因子、尺度因子分别控制函数波动的范围和频率。尺度因子对GP的预测及不确定度至关重要,距离超过尺度因子的数据点间相关性。
平稳核函数k ( x ⃗ , x ⃗ ′ ) = k ( x ⃗ − x ⃗ ′ ) k(\vec{x}, \vec{x}') = k(\vec{x}-\vec{x}') k ( x , x ′ ) = k ( x − x ′ ) k ( x ⃗ , x ⃗ ′ ) = k ( ∥ x ⃗ − x ⃗ ′ ∥ ) k(\vec{x}, \vec{x}') = k(\|\vec{x}-\vec{x}'\|) k ( x , x ′ ) = k ( ∥ x − x ′ ∥ )
泊松过程
The Poisson Distribution and Poisson Process Explained
马尔可夫
列维过程
随机游走
维纳过程Relation to Wiener process
时间序列技术
时间序列分析基础-定义、均值、方差、自协方差及相关性
Applied Time Series Analysis in Python Time Series Modeling AR, StateSpace
随机游走RW
自回归移动平均ARMA
移动平均MA 自回归AR ARMA/ARIMA
Stationary Random Processes Random Process - TaigaComplex Does the autocorrelation function completely describe a stochastic process? Generating coloured noise to simulate physical processes
Astrophotography Basics: SNR