Agentic AI

智能体 Agent 是能在一定程度上自主完成任务的 AI 模型。智能体基础的设计模式是对任务的拆解规划及对输出结果的反思迭代,而工具使用是其与环境自主交互的核心。上述任务拆解、反思迭代及工具使用都可以交由智能体自主决策,由此产生了不同自主程度的智能体。细想一下,其实人类处理日常任务也是完全相同的逻辑。另一方面,Agent 本身也可作为工具(人不应是工具😭),从而实现多智能体协作。最后,高效构建 Agent 的基本原则是小步快跑,关键是建立有效的评估系统,快速定位问题、反馈迭代。
Introduction
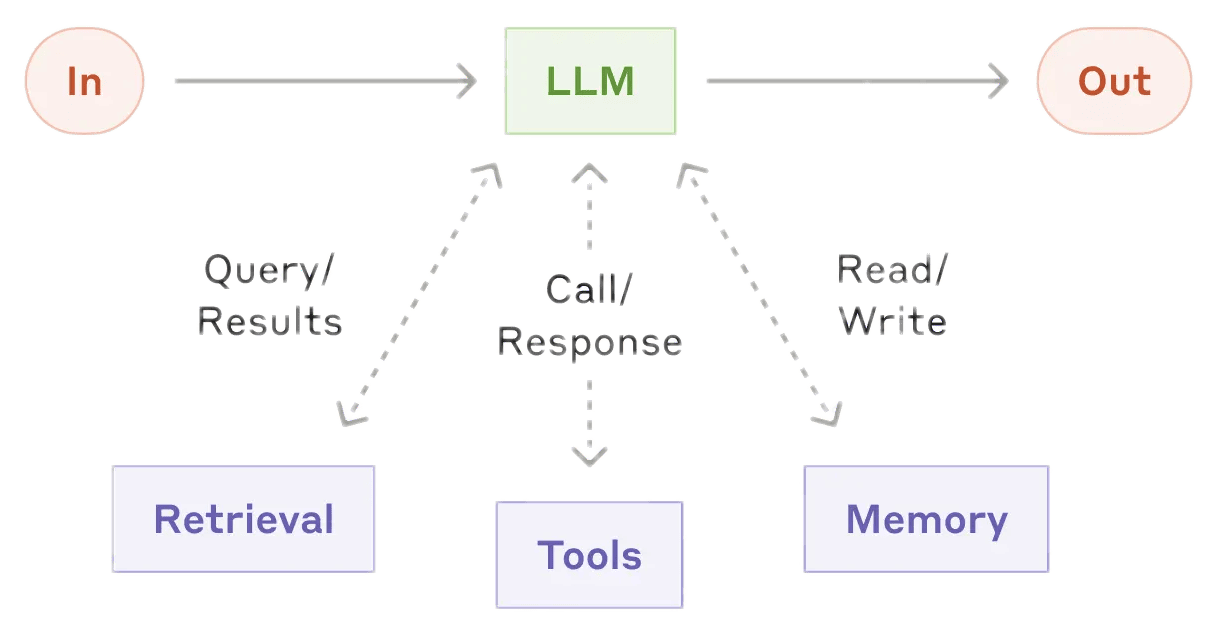
- Models + Tools 工具增强的大模型是自主化AI或智能体的基础
某种意义上甚至可以任务认为 Agent = Models + Tools。其中大模型包含基础的语言模型,也包括图像文字识别以及音视等多模态模型,工具则包含信息检索RAG、记忆管理、程序执行以及通过API(MCP协议)对更多程序的调用。
- Task → Workflow 构建智能体的起点是任务拆解,将复杂问题转化为可操作的流程。
最初接触程序算法时,通常会举生活中“烧水泡茶”流程的例子。对于智能体而言,一切似乎回到了起点,需要的就是现实世界任务的“算法”。O*NET Online上有很多现实工作粗略的任务拆解。
Claude 的 Skills 个人理解就是针对常见原子任务的预定义工作流,由模型按需调用。Skills 包含任务的分解指示,并附带相关的资源工具等,通过人类经验加持提升了工作流单元的可靠性,而通过模块化的组合复用又可构建出更复杂的工作流。其更重要的意义在于标准化、可扩展以及渐进式披露(progressive disclosure),未来AI或许可以自主总结工作模式,参照标准创建及更新技能文件。 - 当然问题拆解这一步本身也可交由AI决策,并由此产生了不同自主程度的智能体。
简单应用可将所有流程硬编码到智能体代码中,最高级形式则是AI全权负责,自主决策处理流程、使用甚至创建必要工具,这类智能体难度更大,目前还不是很成熟,行为上有更多不确定性,也更易出错。

- Evaluation 高效构建智能体的关键在于清晰有效的评估,在实践中快速反馈迭代。
The ability to evaluate the agentic workflow is key to building them effectively.
评估可通过预期效果对应的客观指标或AI模型主观打分实现,且除了最终结果也要关注中间输出,以便有效定位问题、改进流程。 - 智能体核心设计模式 Design Patterns
- 反思 Reflection:将AI的输出结果或运行时报错返回给AI,迭代提升
- 工具 Tool-Using:调用工具API (MCP, Model Context Protocol)
- 计划 Planning:自主决策拆解问题,将复杂问题转化为操作流程
- 协作 Multi-Agent:多个智能体分别负责不同角色,相互协作
Reflection
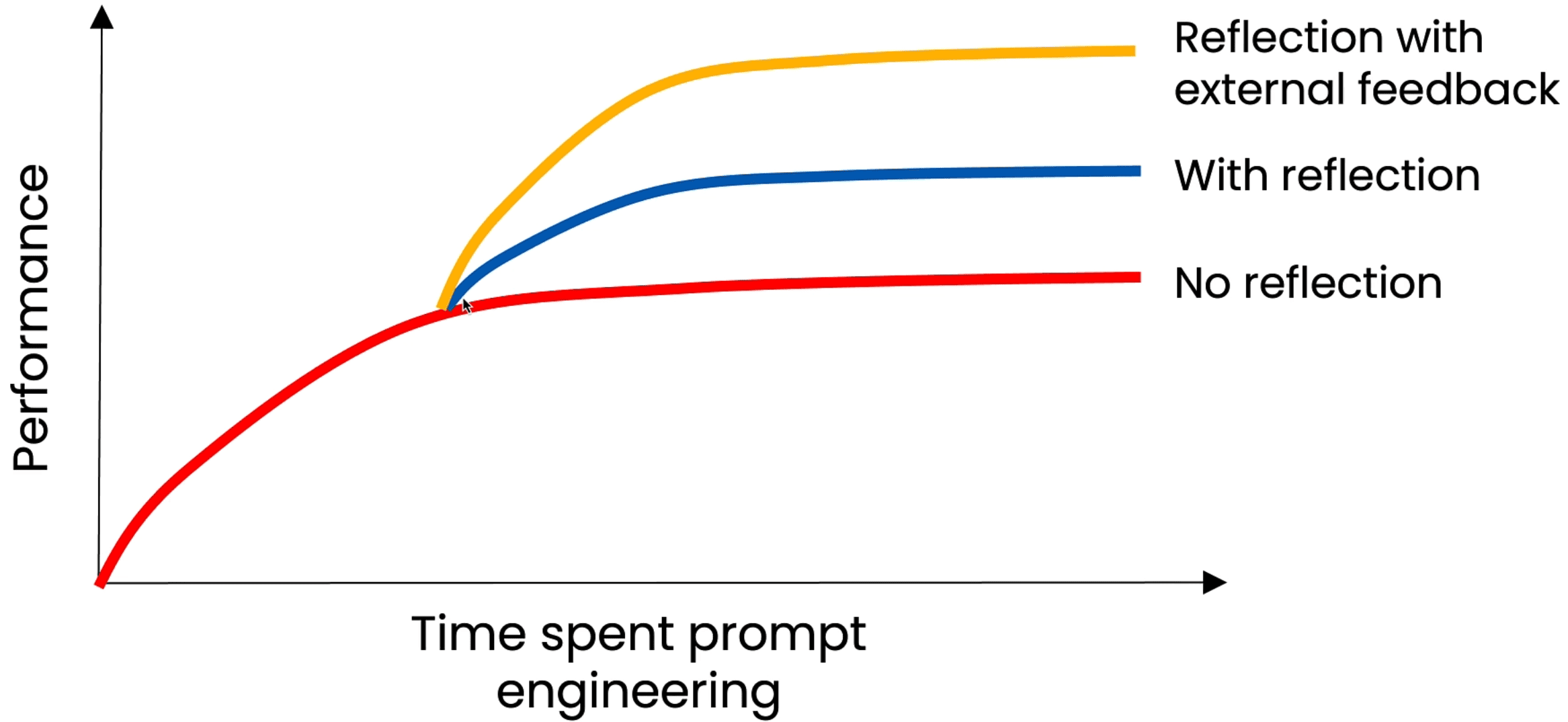
- 显式反思:明确引入反思步骤,指定反思核查的准则
- 评估效果:量化确认反思提升,对比不同Prompt结果
- 主观评估:使用AI模型基于预定标准(rubric)进行评分
注意AI有先验偏见,容易偏向前一结果(Position bias)。因此相比于对比选择,基于给定标准或要点评分,结果相对更可靠。此外AI模型也不擅长准确赋分,整体0-5打分,不如对5个标准分别0-1打分,之后手动求和。 - 信息反馈:分析结果并向模型反馈额外信息,如事实检查、规范审查、运行报错等
Tool-Using
Just like humans, LLMs can do a lot more with access to tools.
- 技术上是AI在输出文本中请求调用工具,而非直接调用工具
- 通过系统prompt为AI提供可用工具列表,同时指定工具调用的标示性输出格式
- 在工作流中插入模型输出检测,检测工具标示,执行接口调用,将结果反馈给AI
1
2
3
4
5
6
7
8'''system prompt: You have access to a tool called `myfunc`. To use it,
return the following exactly: "FUNC_MYFUNC: myfunc(parameters)" '''
reponse = client.responses.create(model, system_prompt, input_text)
history.append(response.output)
if "FUNC_MYFUNC" in reponse.output_text:
result = myfunc(parameters)
history.append(result)
reponse = client.responses.create(model, system_prompt, input_text=history) - 示例仅展示核心逻辑,现代AI应用开发框架都提供了更完善的工具调用支持
系统prompt现实中只需提供函数JSON描述,包含名字、功能介绍、参数等信息
开发者无需手动调用函数,直接使用API即可,但其背后实现本质仍是上述逻辑1
2# https://platform.openai.com/docs/guides/tools
reponse = client.responses.create(model=..., tools=..., input=...) - 代码执行:
exec(可用于上下文隔离、但非沙盒)、E2B、Docker - 模型上下文协议 (Model Context Protocol, MCP)
AI工具需要编写函数实现功能并添加JSON描述,MCP则是统一的交互规范,以实现工具的通用共享。MCP最初设计目标是获取外部数据或上下文,如网络访问、文件获取、数据库查询等,因此称为上下文协议,但其设计可实现通用函数调用。协议中AI模型或内置模型的AI应用为客户端(Client),函数或功能实现的供给方为服务端(Server),客户端通过MCP协议访问服务端所提供的外部资源、工具或工作指令(prompt)。MCP不好的是通常相对“重”,工具本身会占用上下文窗口,消耗大量Tokens,有时候还不如直接调用更为轻便的CLI指令。
Evaluation
- 小步快跑:尽快建立原型系统quick and dirty,评估实际效果,持续迭代优化
- 评估技术:客观评估、主观评估
- 对发现的问题,手动构建针对性的评估测试数据集
- 必要时由AI模型参照预期要点/标准进行主观评分
- 注意评估本身的有效性,适时对指标进行迭代优化

- 评估尺度:端到端评估(集成测试) + 执行轨迹追踪(定位问题) + 组件级评估(优化组件)
对效果不佳任务,深入整个流程管线(Tracing),逐个评估工作流中各组件的效果,构建表格记录收集,统计确认薄弱环节,定位最值得优化及最有可能进行优化的组件。评估时注意辨别前一环节效果对当前及后续组件的干扰。除了在完整流程中的确认各组件的表现,还可将组件隔离出来,单独测试、评估、优化。这种简化避免了其它环节干扰,迭代更迅速。最后,有很多针对评估的开源框架可尝试,如OpenAI Evals。
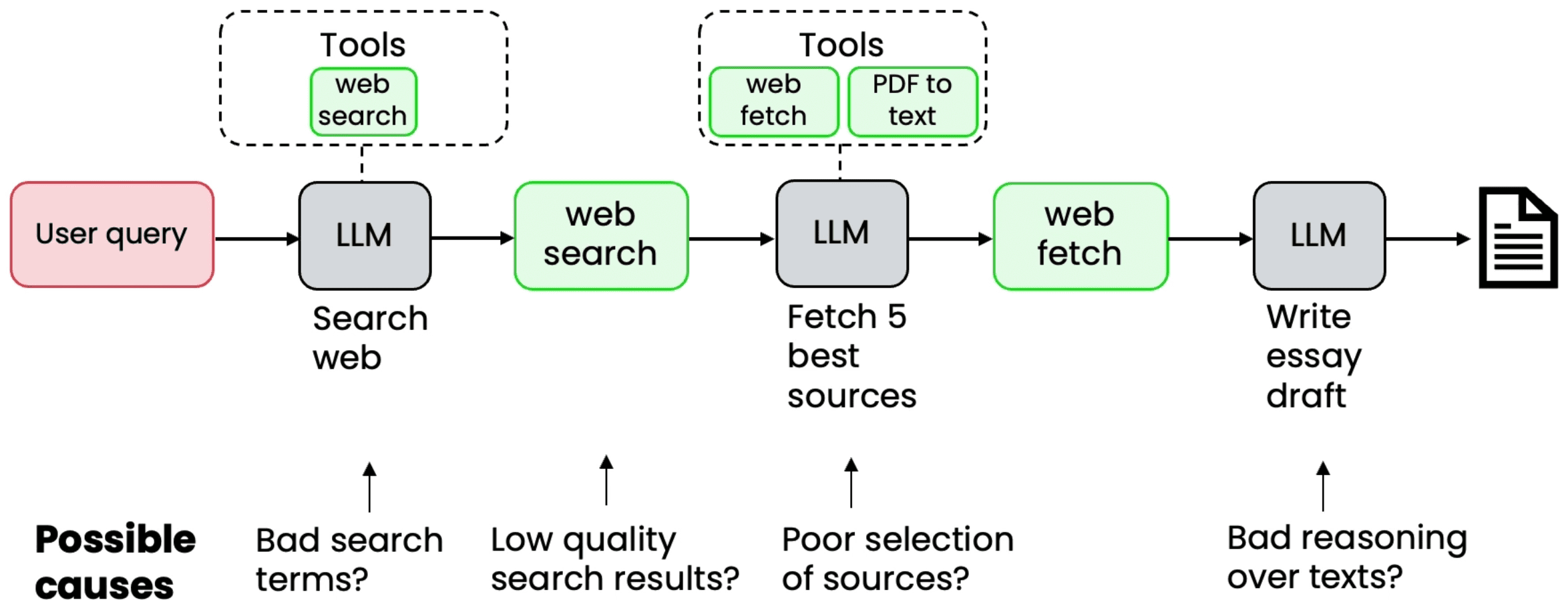 Your skill at choosing where to focus your efforts makes a huge difference.
Your skill at choosing where to focus your efforts makes a huge difference.
- 优化技术:
- 非AI组件:调整组件超参数(检索时间/数据块大小/阈值等)、替换组件
- AI组件:优化prompts、替换模型、任务拆解、模型微调Fine-tuning
- 参考优秀的公开prompts;尝试不同模型,建立各模型擅长领域的直觉
- 成本/延迟:Time; Tokens, API calls, …
优先专注效果,必要时再考虑成本及响应延迟,常见优化方案有并行化、模型路由/替换等
Adv. Agents
- Planning 任务拆解规划
- 使用JSON/XML格式化 Planning in JSON or XML
1
2
3You have access to the following tools:
{description of tools}
Create a step-by-step plan in XML format to carry out the user's request. - 使用代码规划 Planning with code execution
1
2Write python code to solve the user's request.
Return your answer delimited with `<code_python> </<code_python>` tags.
- 使用JSON/XML格式化 Planning in JSON or XML
- Multi-Agent 多个智能体分别负责不同的任务及工具
- 智能体协作核心是Agent as Tool,即将智能体本身作为工具调用
- 线性串联:将工作流中不同任务模块交由不同智能体执行。相比单智能体,一方面可针对具体任务调整,构建擅长特定任务的专用智能体;另一方面,可减少复杂任务中上下文的污染,尤其是考虑到工作记忆容量(窗口长度)有限。
- 中心化管理:由单一智能体负责用户交互、任务拆解规划及结果汇总,统一协调实际执行的子智能体。该模式下智能体调度完全等同于工具调用,而且类似于工具,子智能体本身也可进一步交由管理智能体根据任务需求自主创建。
- 去中心协作:智能体平等合作,均可与用户交互,任务在不同智能体间切换转移
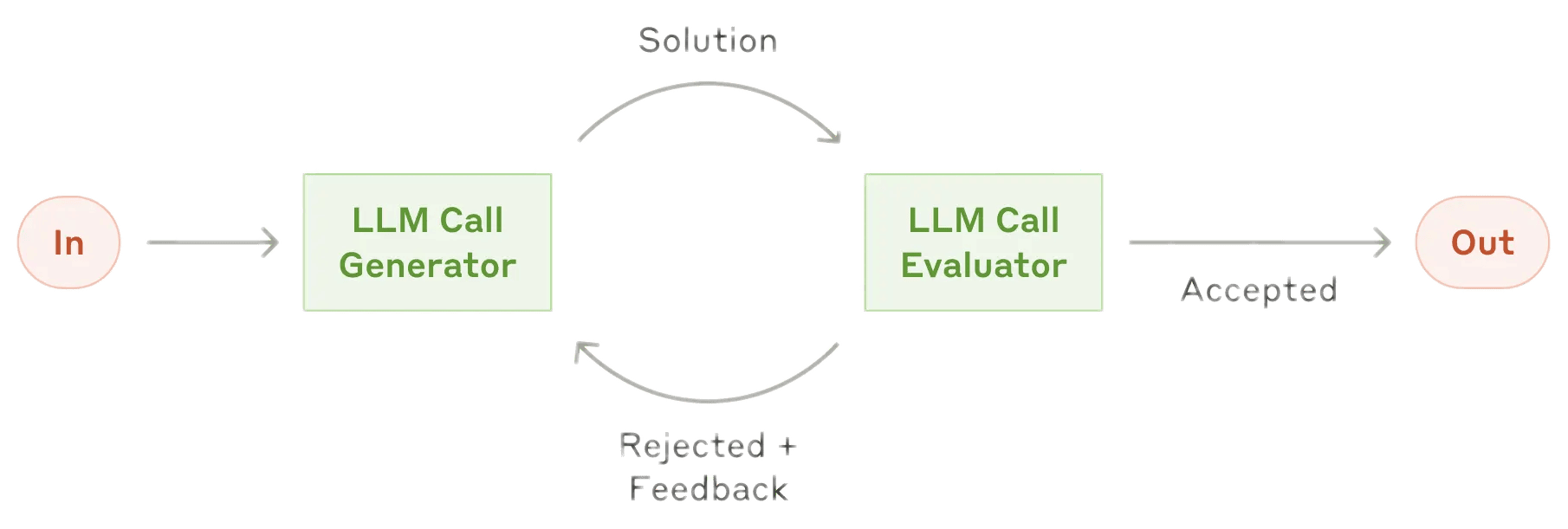
- 反馈回路:将“反思”交由单独智能体执行,负责生成和评估的智能体交互迭代
- Memory 记忆管理课程中未涉及,但个人认为是Agent的核心之一,也是目前的热点
严格意义上“记忆管理”也可算作是工具的使用,但其重要性值得单独强调- 工作记忆 Context:即当前会话上下文,包括最近的对话历史、工具调用、反思评估等。是AI在长线对话或任务中记录进度、保持有序的核心。对于复杂任务,上下文可能超出窗口长度,此时还需进行上下文压缩,类似内存管理。子代理也是实现上下文压缩的有效手段,中心模型负责主线任务相关的核心上下文,支线任务交由子代理,避免上下文干扰。而工作记忆也确实类似电脑内存,仅针对当前会话,结束后全部清零。
- 长期记忆 Memory:可理解为与智能体更深度融合的信息检索增强(RAG)。使智能体能够基于历史构建知识库,将过往的交互过程、成功策略或失败尝试转化为支撑未来决策的经验,更好的吸收信息、适应环境,以及提供个性化的反馈。这可能需要类似于“海马体”的模块负责将工作记忆转化为长期记忆,最近的ReasoningBank, Artificial Hippocampus Networks都是类似探索。最近的 DeepSeek-OCR 工作则提示我们或许“图像化”记忆要比直接的文本嵌入更高效。当然也可能需要的只是更强的大模型。
扩展阅读
Don’t Build Multi-Agents
Building effective agents | Anthropic
A practical guide to building agents | OpenAI
Effective context engineering for AI Agents | Anthropic
Frequently Asked Questions (And Answers) About AI Evals
The Unreasonable Effectiveness of an LLM Agent Loop with Tool Use
Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systems